What is AWS Glue? #
완전 관리형(=serverless) ETL(extract, transform, load) 서비스
- 데이터 카테고라이징, 정리, 보강
- 데이터 다양한 data store, data stream 간 이동
구성 요소 #
| 구성 요소 | 설명 |
|---|---|
| Data Catalog | Central metadata repository |
| ETL engine | python, scala code 등을 자동으로 생성하는 ETL Engine |
| Scheduler | 의존성을 핸들링하고, Job monitoring, retry 를 처리할 수 있는 유연한 스케줄러 |
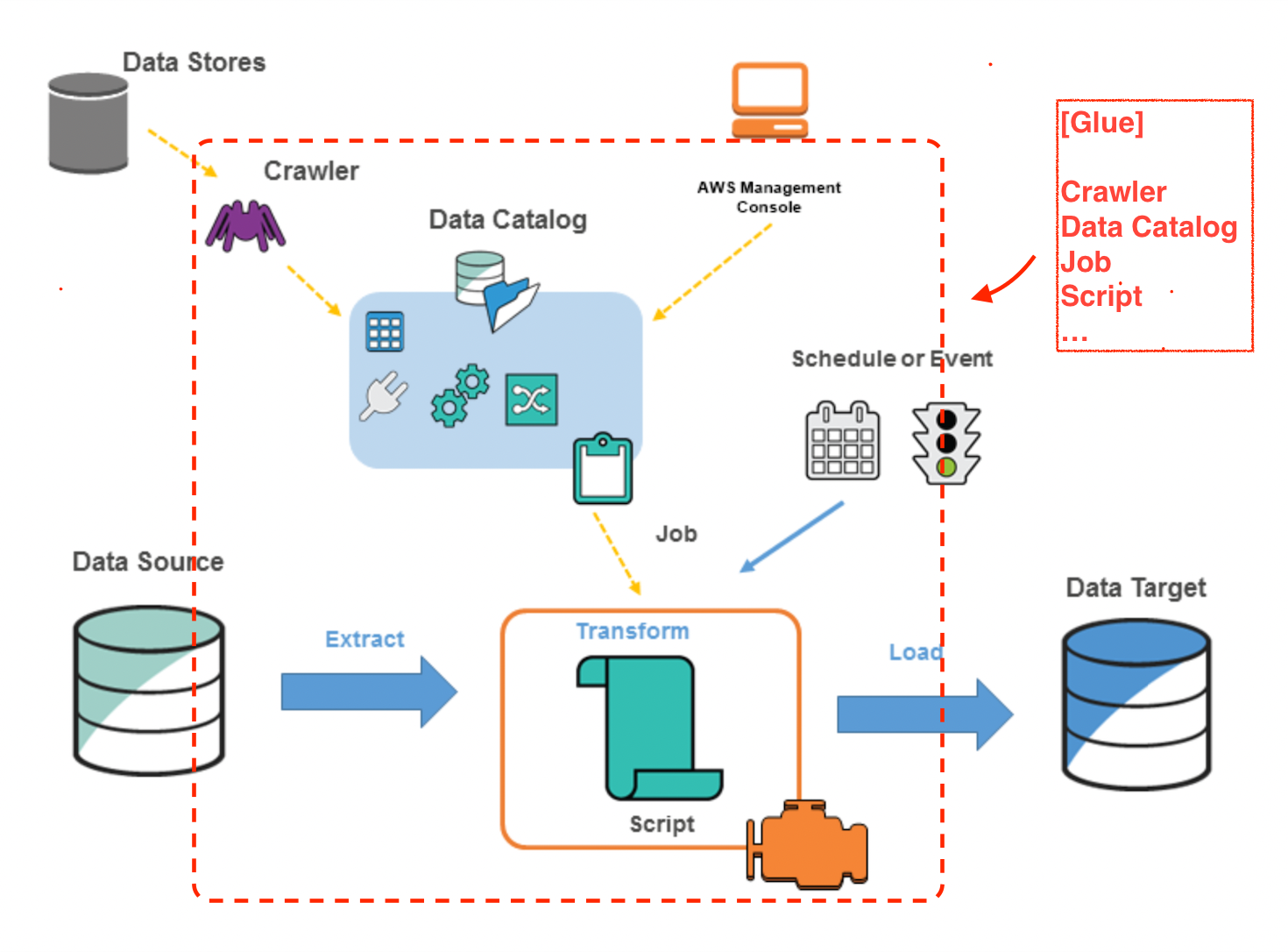
특징 #
- semi-structured data(반구조화된 데이터)와 함께 처리되도록 설계되었다.
- ETL 스크립트를 사용할 수 있는
dynamic frame(동적 프레임)이라는 컴포넌트(?)
- ETL 스크립트를 사용할 수 있는
- Glue Console 을 이용해서 데이터를 발견(discover), 변환(transform), 검색/쿼리가 가능(make it available for search and querying)하게 할 수 있다.
- 마지막 문장인 “쿼리가 가능하게 할 수 있다.” 가 중요한 것 같다. 실제 데이터를 테이블에 삽입하는 방식이 아니라, “Data Store 에 있는 데이터를 검색할 수 있게 하는 것” 을 알려주는 것 같기 때문이다.
그 외 다양한 특징/이점은 AWS 공식문서를 살펴보자. 다만, 아래 내용은 중요하니 참고하자.

Dynamic Frame #
데이터를 row, column으로 구조화하기 위해 사용되는 데이터 추상화인 Apache Spark의 dataframe 과 유사하다.
- 각 레코드는 self-describing 하다는 것을 기반으로, 초기 데이터 스키마 설정/설계가 필요하지 않다.
- 예를 들어, json 데이터를 분석해, 분석한 스키마를 기반으로 테이블(파티션)을 생성하는 이 기법? 을 의미하는 단어인 것 가다.
Dynamic frame ↔ Spark dataframe 간에 컨버팅이 가능하다.
- Glue, Spark 모두 활용할 수 있는 이점이 있다.
Crawler #
Crawler 는 Data Stores(S3, …) 를 분석한다.
- 파티션, 스키마를 파악하여 Data Catalog Table 을 생성한다.
- Table 은 파티션 정보를 가지고 있는데, 이 파티션 정보가 중요하다.
- 데이터를 조회할 때 스캔한 파티션을 기반으로 데이터 조회가 가능하다.
- 데이터를 조회할 때 스캔한 파티션을 기반으로, DataStore 를 조회 & 결과를 반환하는 것 같다.
- 따라서, 한번 스캔된 파티션(= DataStore 쪽에)에 데이터를 추가/삭제하면 바로바로 확인할 수 있다.
예시: 스캔된 파티션 #
Data Store(ex: S3의 Path A) 해당 파티션(Path)에 대해 이미 스캔되었다면, (해당 파티션, path 위치에)S3에 데이터를 삽입,삭제하면 바로바로 조회가 가능하다.
예시 : 스캔되지 않은 파티션 #
반면에 DataStore(ex: S3의 Path B) 해당 파티션(Path)에 대해 한번이라도 스캔되지 않았다면, 이는 크롤러에 의해 최초 한번은 스캔되어야 한다. 그렇지 않으면 사용할 수 없다.
‘Deprecated’ #

https://docs.aws.amazon.com/glue/latest/dg/crawler-configuration.html
처음에는 위(DeleteBehavior)에서 언급한 ‘a deleted object’ 가 S3의 object 인 줄 알았는데, Data Store 를 의미하는 것 같다. 즉, Data Store 에 정상적으로 접근하지 못하는 경우를 의미하는 것 같다.
- 해당 Path 를 찾지 못해 접근하지 못하거나, 권한이 없을 때 등의 상황이 있겠다.
참고 #
테스트 해보니 한번 Deprecated 마킹되면 정상적으로 돌아와도 마킹이 풀리지 않는 것 같다.
예시: 로그 #
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] BENCHMARK : Running Start Crawl for Crawler {크롤러명}
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] BENCHMARK : Classification complete, writing results to database {DB명}
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] INFO : Crawler configured with SchemaChangePolicy {"UpdateBehavior":"LOG","DeleteBehavior":"DEPRECATE_IN_DATABASE"}.
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] INFO : Table {테이블명} is marked deprecated because a matching schema was not found at the table's location.
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] INFO : Found partition of table {테이블명} with partition values [1, A, C, 2] with no matching schema at the partition's S3 location
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] BENCHMARK : Finished writing to Catalog
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] INFO : Run Summary For TABLE:
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] INFO : UPDATE: 1
2022-01-01T00:00:00.000+09:00 [0123456-7890-1234-5678-1234567890] BENCHMARK : Crawler has finished running and is in state READY

https://docs.aws.amazon.com/glue/latest/dg/console-tables.html
ㄴ (깔끔하게 유지하기 위해서) 삭제 후 재생성하는 것도 방법이 될 수 있을 것 같다.
When should I use AWS Glue? #
- You can use AWS Glue to organize, cleanse, validate, and format data for storage in a data warehouse or data lake.
- You can use AWS Glue when you run serverless queries against your Amazon S3 data lake.
- You can create event-driven ETL pipelines with AWS Glue.
- You can use AWS Glue to understand your data assets.
AWS Glue 는 S3의 데이터를 카탈로그화 할 수 있다. 카탈로그화를 통해 Athena, Redshift Spectrum으로 쿼리(검색)가 가능하게 만들 수 있다. 여기서 말하는 카탈로그화란, 데이터에 대한 메타데이터를 만드는 것으로 이해했다.
" AWS Glue can catalog your Amazon Simple Storage Service (Amazon S3) data, making it available for querying with Amazon Athena and Amazon Redshift Spectrum. “
Glue Crawler를 통해, 메타데이터가 계속해서 동기화될 수 있도록 할 수 있다. 카탈로그화 이후 Athena, Redshift Spectrum 은 AWS Glue Data Catalog 를 통해 S3에 직접적으로 쿼리할 수 있게 된다.
AWS Glue 를 사용하면 여러 DataStore 에 각각 로드하지 않고 하나의 인터페이스(Athena, Redshift Spectrum)를 통해 데이터를 검색/분석할 수 있게 된다.
Glue Data Catalog 관련 내용 추가 #
Glue Data Catalog 내 테이블에는 실제 데이터가 포함되어 있지 않다. 메타데이터만 포함하고 있다.

Glue → S3 Access Denied(403) 오류 발생 관련 내용 추가 #
Glue -> S3 Access Denied 403 오류 발생 시 아래 글을 확인해볼 수 있다.
AWS Glue 작업에서 403 Access Denied 오류가 반환되는 이유는 무엇입니까?
- AWS Identity and Access Management(IAM) 역할에 버킷 액세스에 필요한 권한이 없습니다. (IAM Role)
- Amazon S3 버킷 정책이 IAM 역할에 필요한 권한을 허용하지 않습니다. (Bucket Policy)
- S3 버킷 소유자가 객체 소유자와 다릅니다. (S3 ACLs)
- 객체가 AWS Key Management Service(AWS KMS)로 암호화되었고, AWS KMS 정책이 키 사용에 필요한 최소 권한을 IAM 역할에 부여하지 않습니다. (S3 Encryption)
Amazon Virtual Private Cloud(Amazon VPC) 엔드포인트 정책에 S3 버킷 액세스에 필요한 권한이 없습니다.S3 버킷에 요청자 지불이 설정되어 있습니다.S3 버킷에 대한 액세스가 AWS Organizations 서비스 제어 정책에 의해 제한되었습니다.