OpenSearch 구조 #
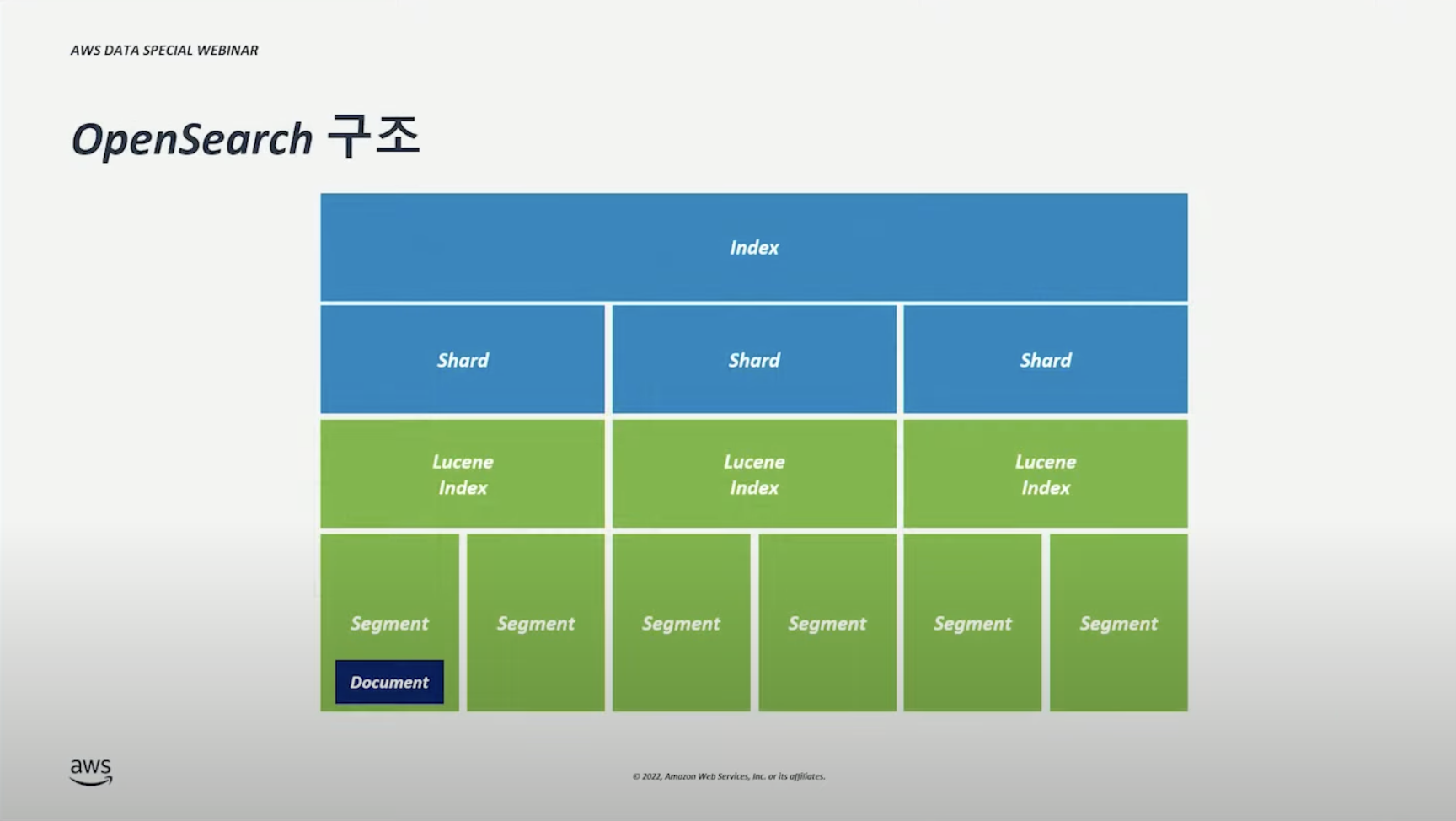
- 파란색 부분(Index, Shard)에 대해서만 이해하고 있다면 일반적인 사용에서 문제가 없다.
- 초록색 부분(Lucene Index, Segment)는 깊은 사용, 성능 최적화 등을 위해 이해해야 하는 부분이다.
Shard #
영상에서, 샤드 = 물리적인 노드 1대1 대응해서 설명하는 것 같다.
즉, 아래 그림은 각각의 물리적인 노드 위에 각 샤드가 있는 것을 가정한다.
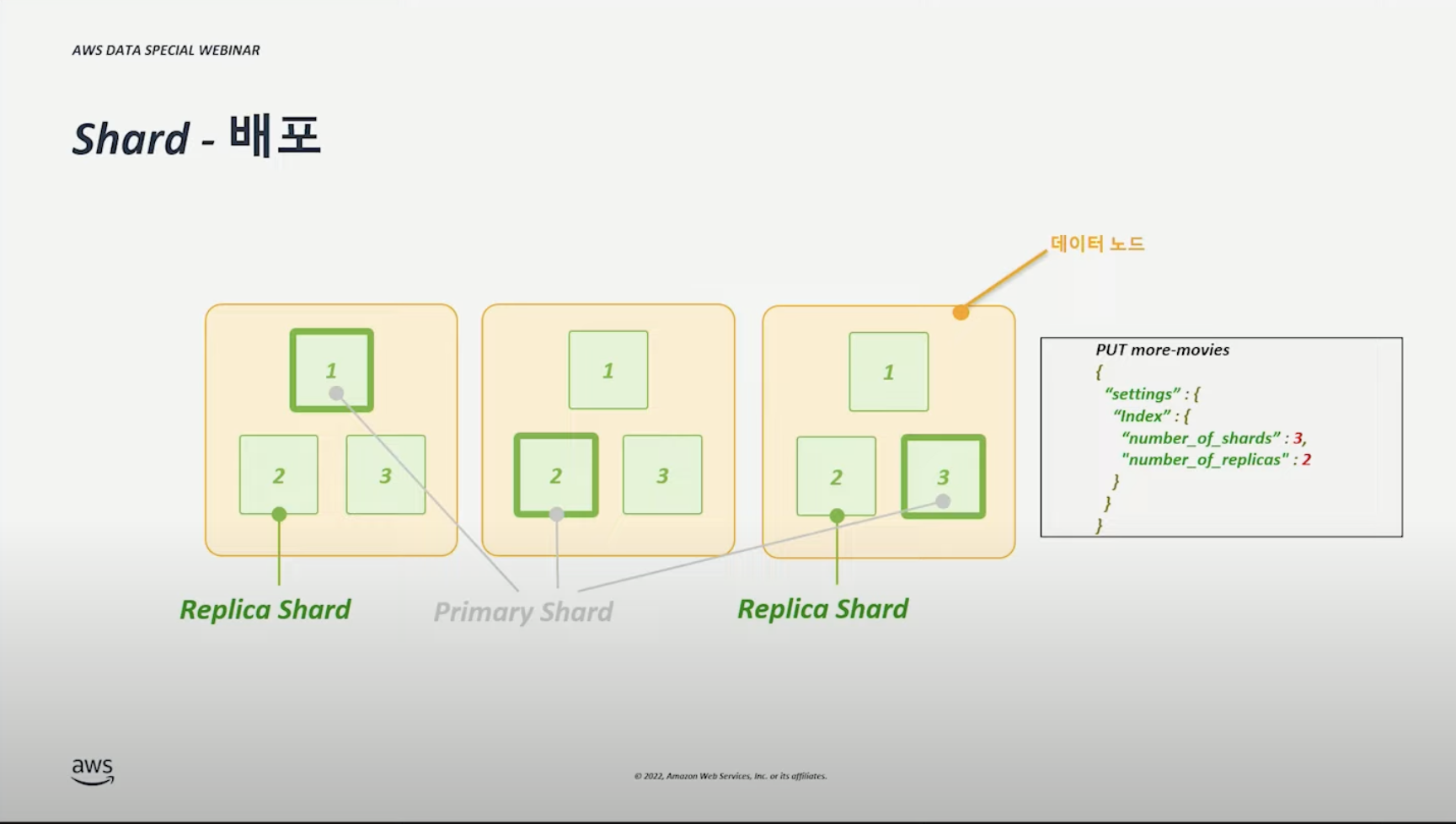
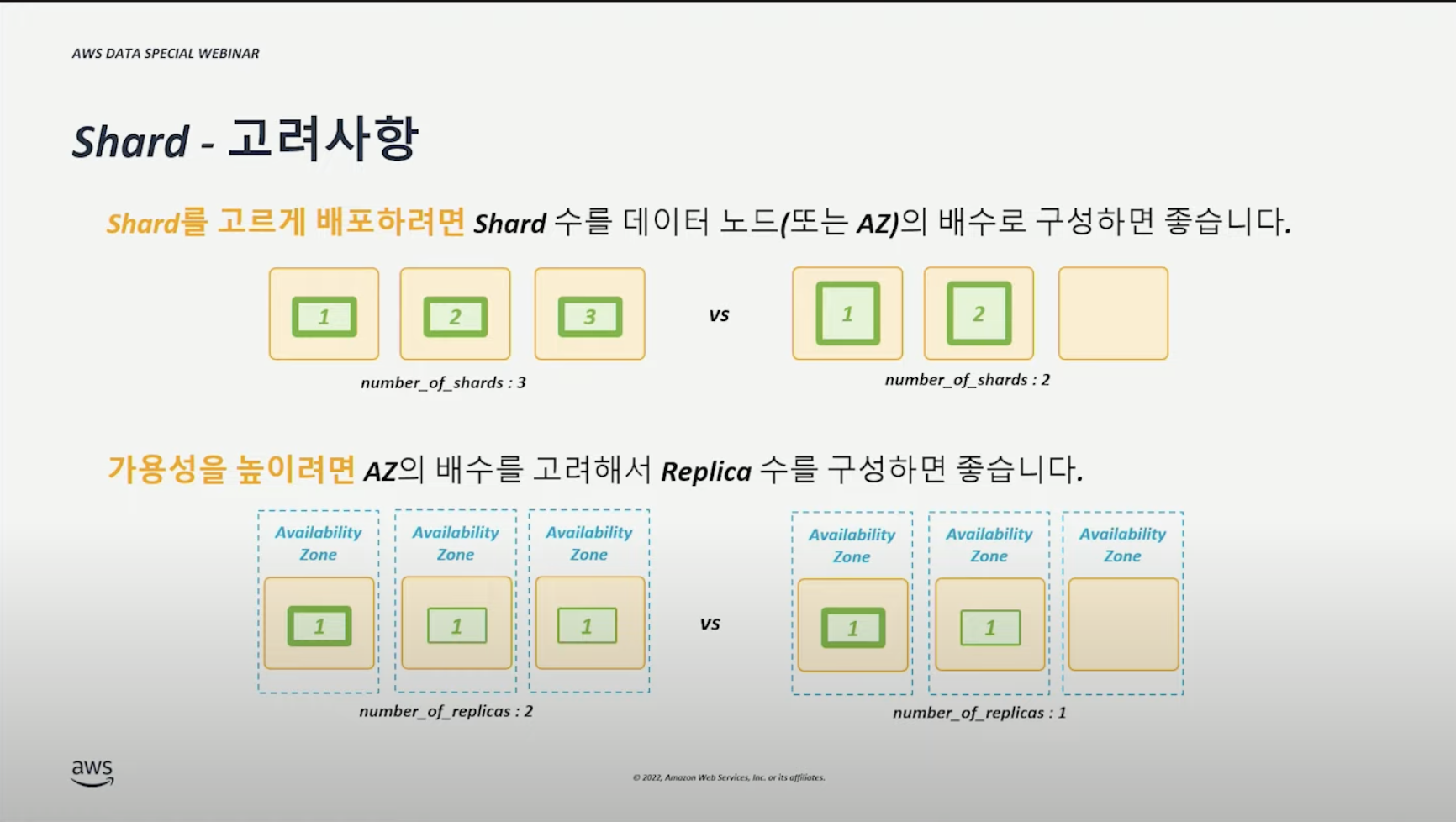
- 샤드의 수 = 데이터 노드(or AZ) x N
- Replica 수 = AZ x N
Index 디자인 #
Index 패턴 #
| 패턴 | 설명 |
|---|---|
| Rolling Index | - 인덱스 기간, 보존 기간이 있고 계속적으로 데이터가 흘러 들어오는 경우 - 오래된 Index 는 보유 기간에 따라 Warm/Cold 계층으로 마이그레이션, 삭제 가능 - search-logs-2022, weblogs-2022-07, … |
| Long-Term Retention Index | - 같은 Index에 소스 데이터 저장 - 문서의 업데이트, 삭제가 필요한 경우가 많음 - movies, internal-docs, website-contents, … |
Index 사이즈 관리 #
| 관리 | 설명 |
|---|---|
| 사이즈 기반 로테이션 | - 크기 추정 불가 (특정 사이즈가 넘어가면 새로운 인덱스로 생성한다.) - ‘삭제’에 대한 요구사항 없음 - 동일한 shard(인덱스) 크기 유지 - index-A-000000, index-A-000001, … |
| 기간(시계열) 기반 로테이션 | - 크기 추정 가능 - ‘삭제’에 대한 요구사항 있음 (특정 기간에 대한 삭제가 용이하다.) - 기간 기준 검색 요구사항 있음 - index-A-2022-09-01, index-A-2022-09-02, … |
Index 로테이션 빈도에 따른 주의사항 #
매일마다 일정한 데이터 흐름 속도(양)으로 들어오더라도, 로테이션 빈도에 따라 Shard 구성이 달라질 수 있다.
예를 들어, 일일 데이터 양 30GB가 유입되고, Shard 사이즈를 50GB라고 가정하자. (계산 편의를 위해 Primary 샤드만 고려한다.)
| 경우 | 샤드 수 |
|---|---|
| Daily rotation | 30GB * 1.1 / 50GB = 0.66 = 1 Shard |
| Weekly rotation | 30GB * 1.1 * 7 / 50GB = 4.62 = 5 Shard |
| Monthly rotation | 30GB * 1.1 * 31 / 50GB = 20.46 = 21 Shard |
즉, 한달 기준으로
- daily로 인덱스를 생성하면, 30개의 샤드(인덱스)가 필요하다.
- monthly 인덱스 생성하면, 21개의 샤드(인덱스)가 필요하다.
적합한 Domain(= Cluster) 구성 예측 #
Opensearch 사용을 시작하면 기본적으로 아래와 같은 형태와 같이 배포된다.
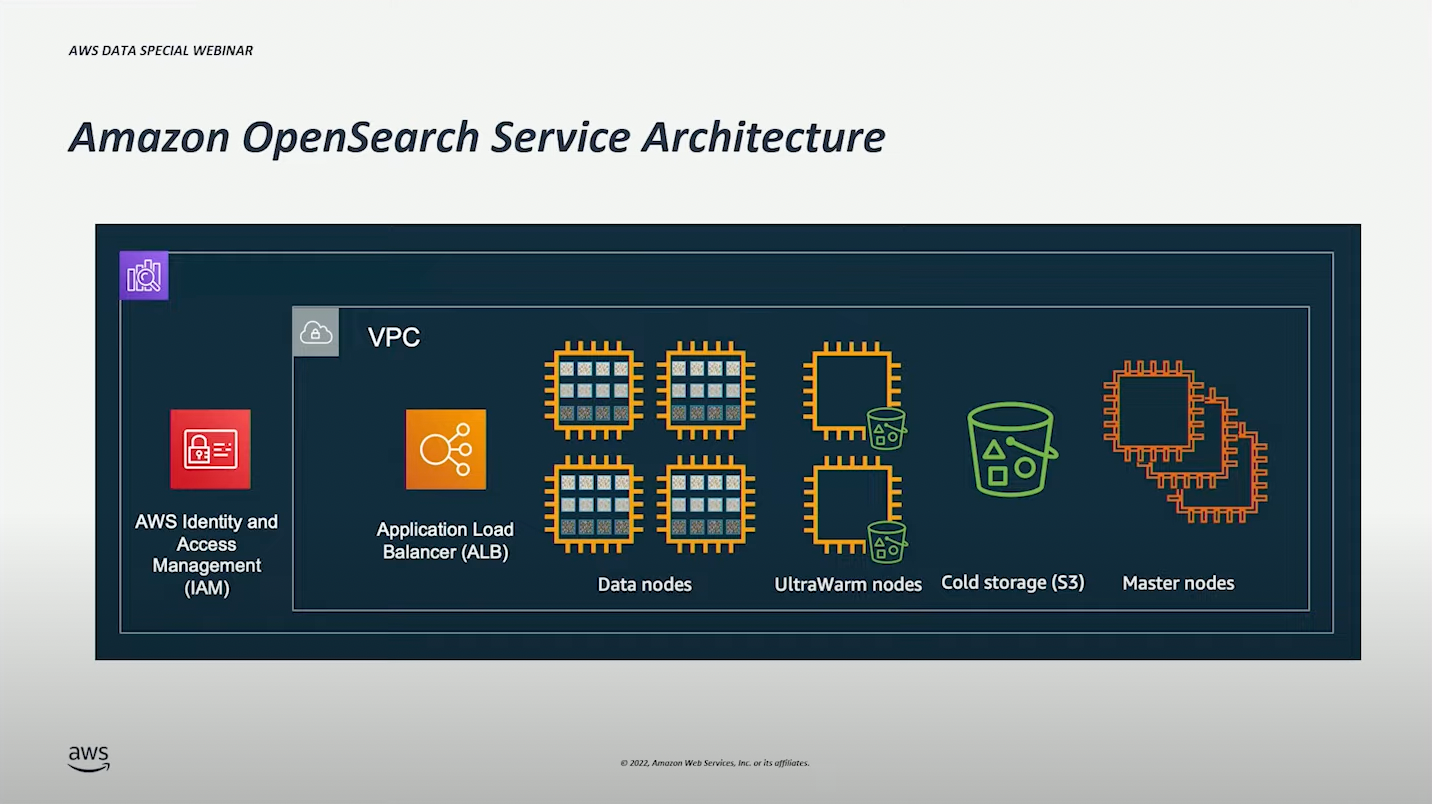
처음 사용할 때는 각종 노드를 어느정도(인스턴스 타입)로 구성하고, 몇 개로 구성해야할 지 예상하는 것이 어렵다.
Domain(= Cluster) 구성 예측 #
- 스토리지 크기 를 예측해본다.
- (1번을 기반으로) Shard 수 를 예측해본다.
- (1, 2번을 기반으로) vCPU / Memory 를 예측해본다.
- (3번을 기반으로) Data Nodes (인스턴스 타입) 을 예측해본다.
- (4번을 기반으로) Master Nodes (인스턴스 타입) 을 예측해본다.
말그래도 ‘예측’이다. 실제로 운영하면서 모니터링하고 수정해나가야 한다.
Domain 구성 예측 1 - 스토리지 크기 #

| 구성 | 설명 |
|---|---|
| Hot | 검색 빈도 수가 높은 인덱스 노드의 볼륨에 저장한다. |
| UltraWarm | 검색 빈도 수가 중간 정도 되는 인덱스 데이터양은 많지만 낮은 비용으로 검색, 분석할 때 사용할 수 있다. 노드의 로컬 캐시 + S3 Bucket 를 사용한다. |
| Cold | 검색 빈도 수가 거의 없는 인덱스 S3에 저장한다. 인스턴스가 없으므로 검색할 수 없다. UltraWarm 으로 마이그레이션하여 검색하거나 S3 데이터를 다운로드 할 수만 있다. |
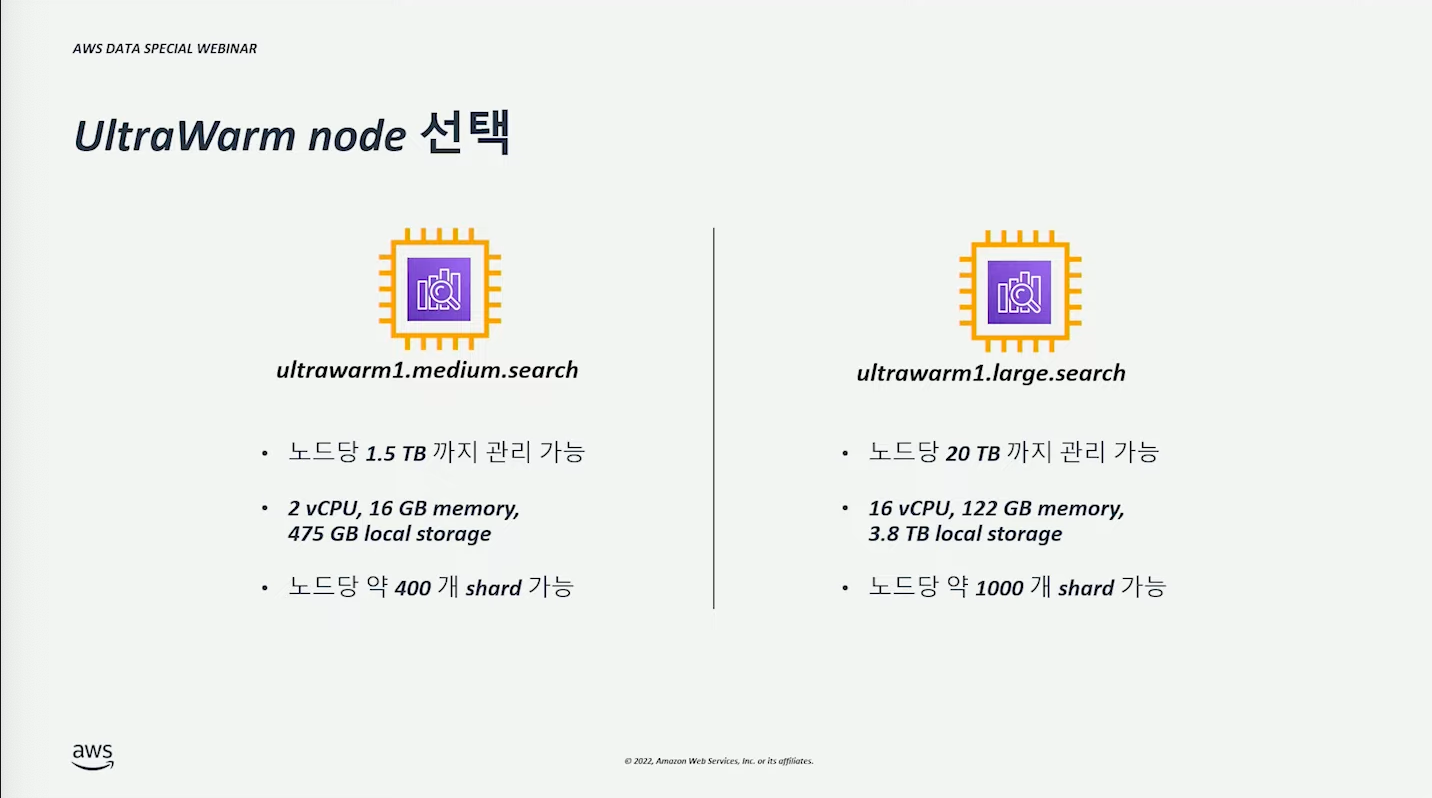
UltraWarm 노드 #
데이터양은 많지만 낮은 비용으로 데이터 검색, 분석하고 싶을 때 (이 구성으로)사용할 수 있다.
다만, readonly 이므로 write 가 필요한 경우에는 hot 영역으로 마이그레이션해야 한다. (아래 이미지에 나와있는 API 통해 마이그레이션을 간단히 수행할 수 있다.)
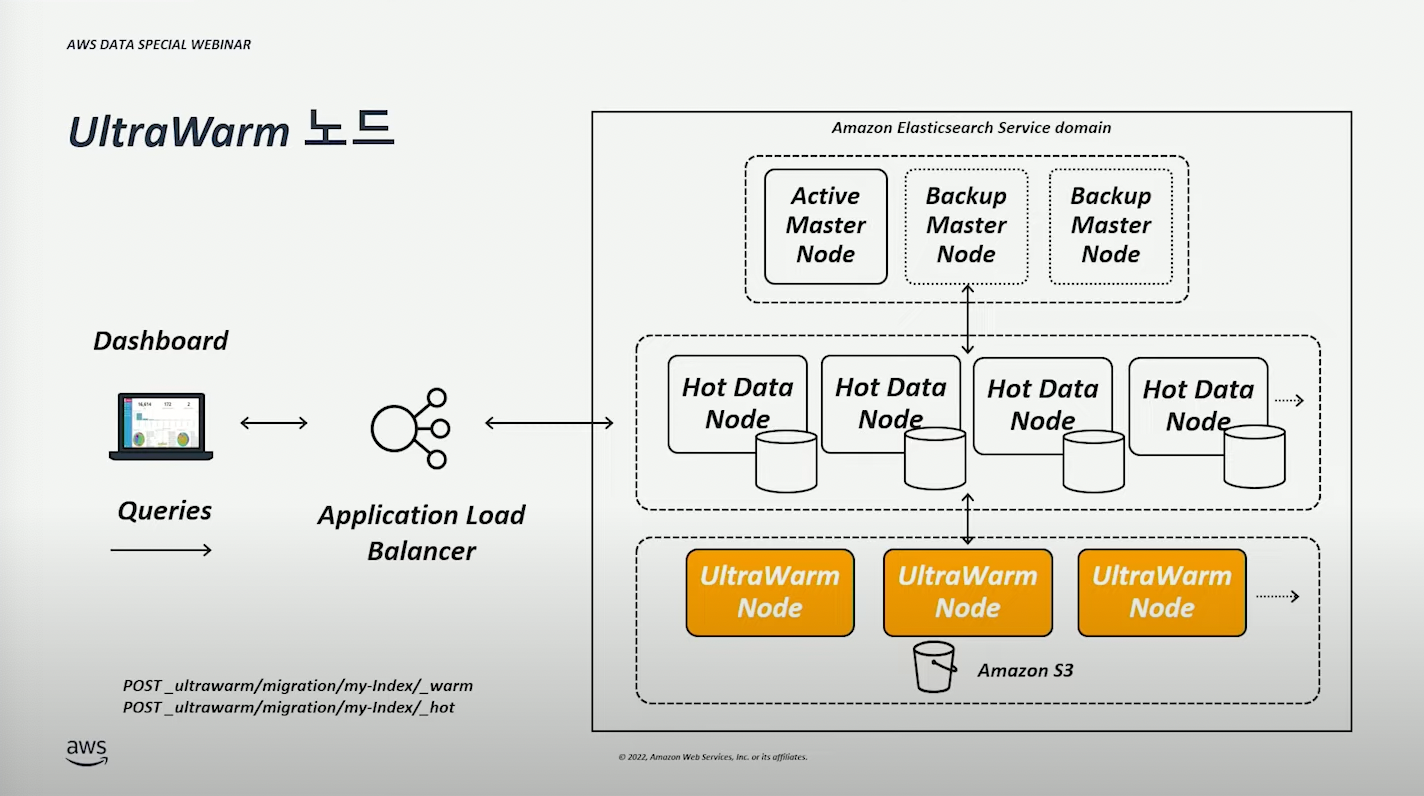
클라이언트가 검색할 때에는 Hot, UltraWarm 노드에서 데이터를 가져온다.
Storage 크기 예측 (예시) #
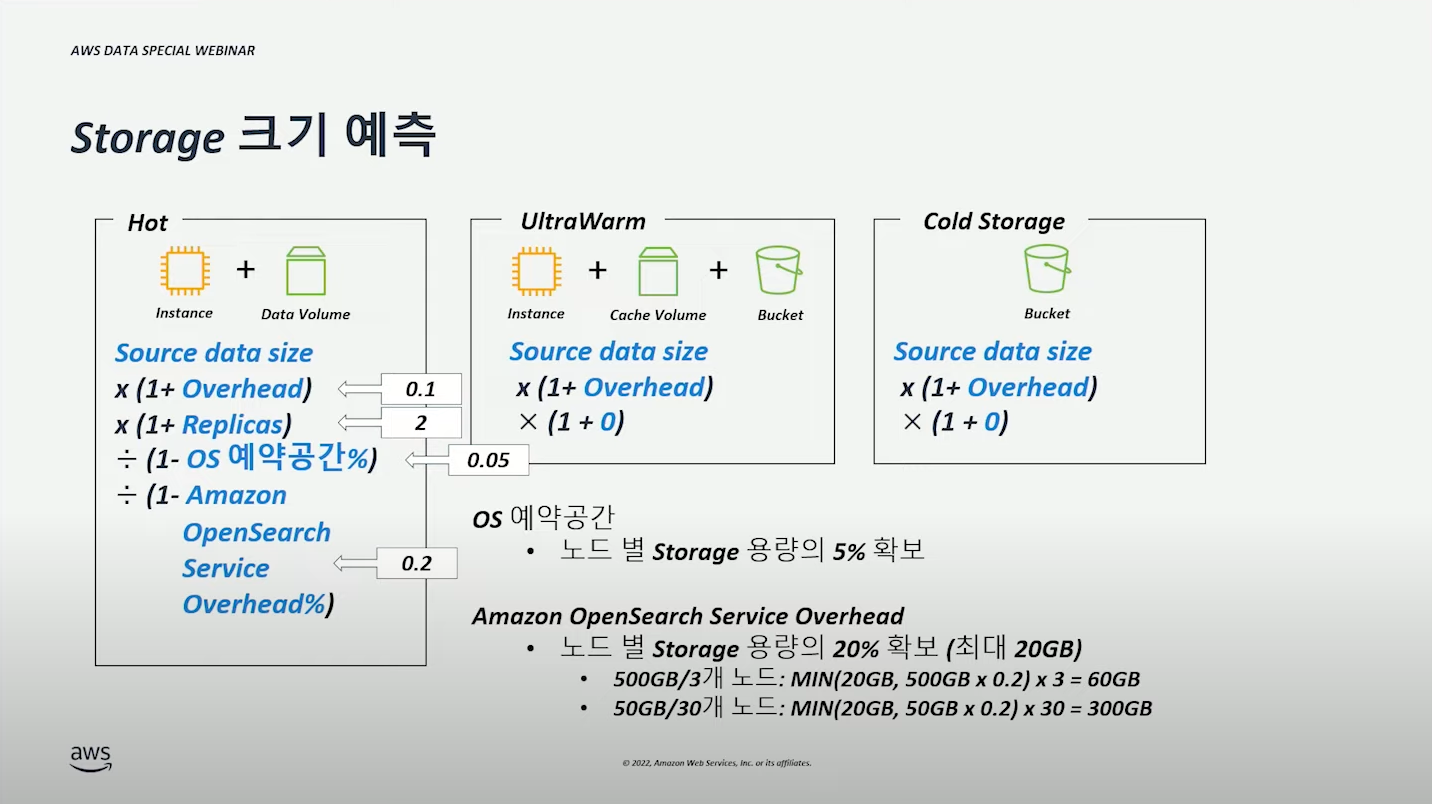
| 기준 | 설명 |
|---|---|
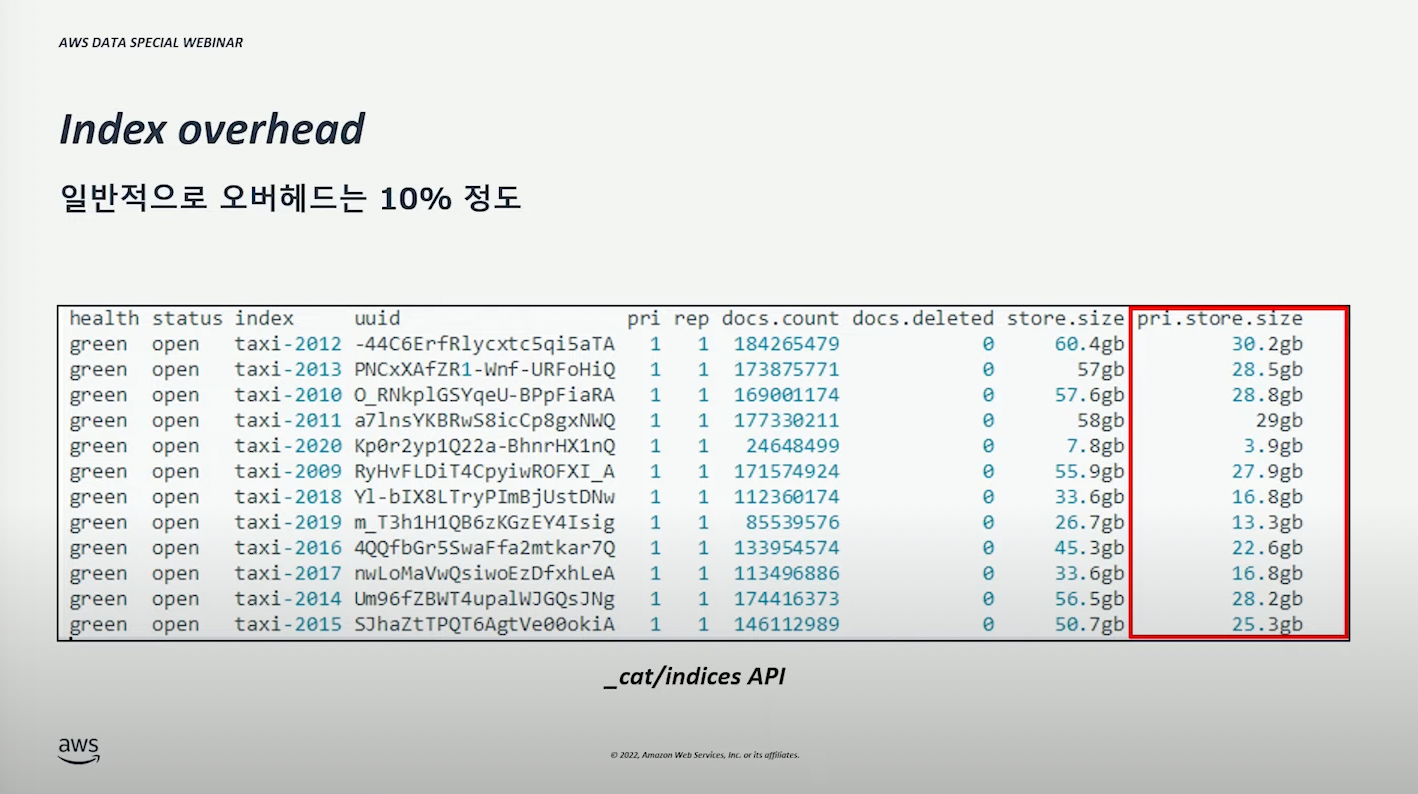
| Indexing Overhead | 보통 10% 잡는다. 10%는 계산의 편의를 위해 보통 설정하는 기준이다. 정확한 계산을 위해서는 _cat/indices API 를 통해 실제 인덱스 사이즈를 확인할 수 있다. |
| Replica | (운영 환경 기준)보통 2개 잡는다. |
| OS 예약공간 | 보통 5% 잡는다. 주요 프로세스를 위한 영역이다. |
| Service Overhead | 보통 20% 잡는다. 노드별 스토리지 용량의 20%를 확보한다. 구성에 따라 20%라는 값이 달라질 수 있다. (위 그림 참고) 큰 용량 x 적은 노드 수가 적은 overhead 를 갖는다. |
UltraWarm, Cold Storage 의 경우에는 인덱스가 S3에 저장되기 때문에 Indexing Overhead만 고려하면 된다.
Domain 구성 예측 2 - Shard 수 예측 #
결론부터 말하면, 완벽한 수(구성)는 없다.
샤드 수가 너무 적어도, 너무 많아도 문제다. 적절한 수를 찾아야한다.
| 케이스 | 설명 |
|---|---|
| 작은 Shard x 많은 수 | 아래와 같은 문제가 발생할 수 있다. - 검색 성능 저하 - 높은 Heap 사용률 |
| 큰 Shard x 적은 수 | 아래와 같은 문제가 발생할 수 있다. - 검색 성능 저하 |

일반적으로 인덱스 사이즈는 위 그림(10GB ~ 30GB, 10GB ~ 50GB)에서 나온 것 처럼 구성(시작)되면 좋다.
Rolling Index 의 경우 새롭게 인덱스를 생성할 때 사이즈를 재조정 가능하므로, 깊게 고려하지 않아도 된다.
Primary Shard 수 #

예제
- 매일 200GB 유입
- 각 Shard 크기 수 30GB
- 매일 Rolling
- 3 AZ 에 3개의 데이터 노드가 분산
- Replica 수 2
계산
| 샤드 | 계산 | 결론 |
|---|---|---|
| Primary | (200GB + 0) * (1 + 0.1) / 30GB x 1 day = 7 shard | 6 or 9 shard (6개를 선택했다고 가정한다.) |
| Replica | primary shard(6, 9) x 2 | 12 or 18 shard per day |
Domain 구성 예측 3 - vCPU / Memory #
vCPU 예측 #

- 일반적인 Workload : 일반적인 상황
- 고부하 워크로드 : 잦은 인덱싱, 검색 요청률 높음, 대용량 검색으로 인한 부하 높은 상황
Memory 예측 #

JVM 에서는 32GB 이상으로 Heap 용량을 주면 오히려 성능이 저하되는 현상이 있음 (Compressed OOP 관련 이슈?)
Domain 구성 예측 4 - Data Node #
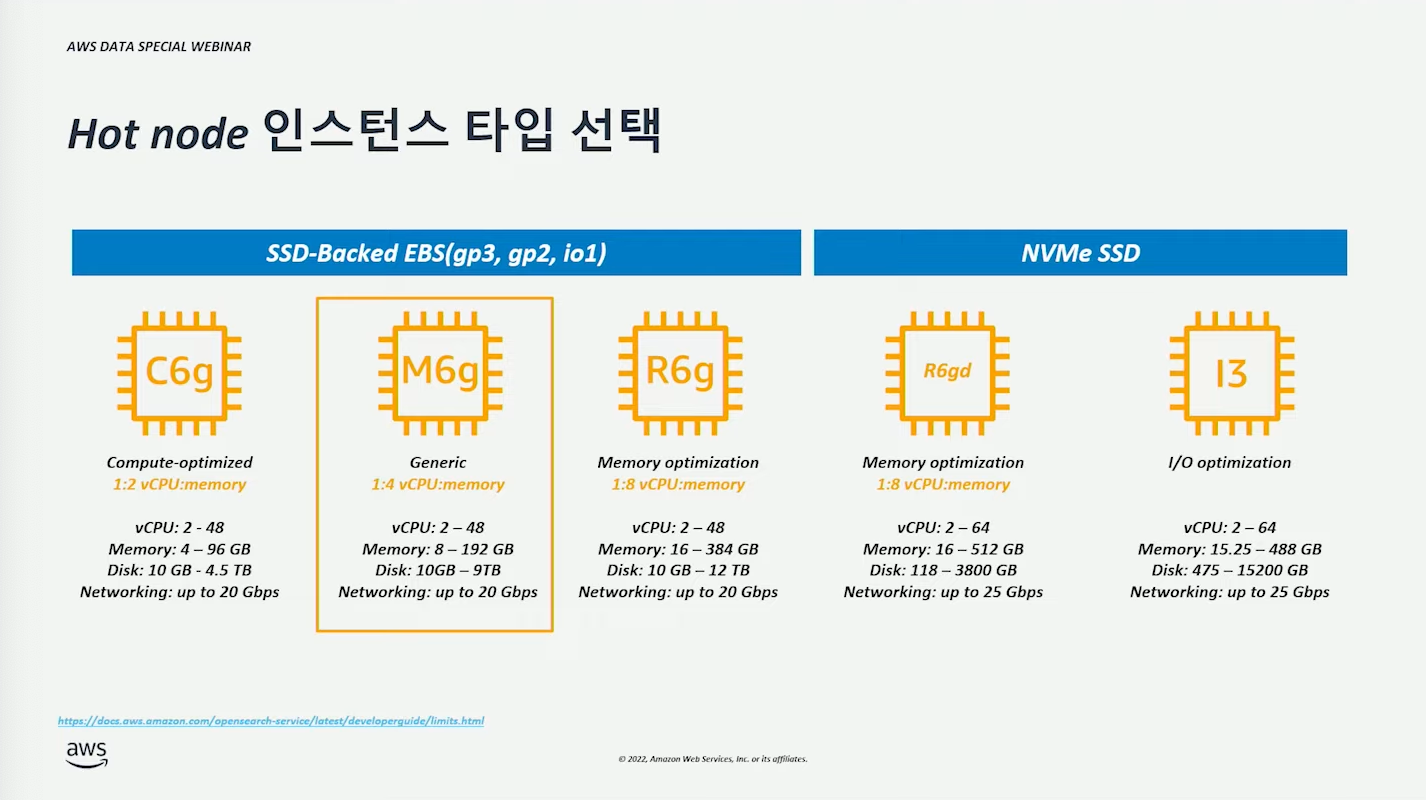
최신 인스턴스 타입을 선택하는 것은 기본이다. (최신 인스턴스 일수록 성능이 좋고 비용이 저렴할 것이다.)
일반적인 상황에서는 m6g 부터 시작해도 좋다고 한다. 어느정도 인스턴스인지 확인해보자.
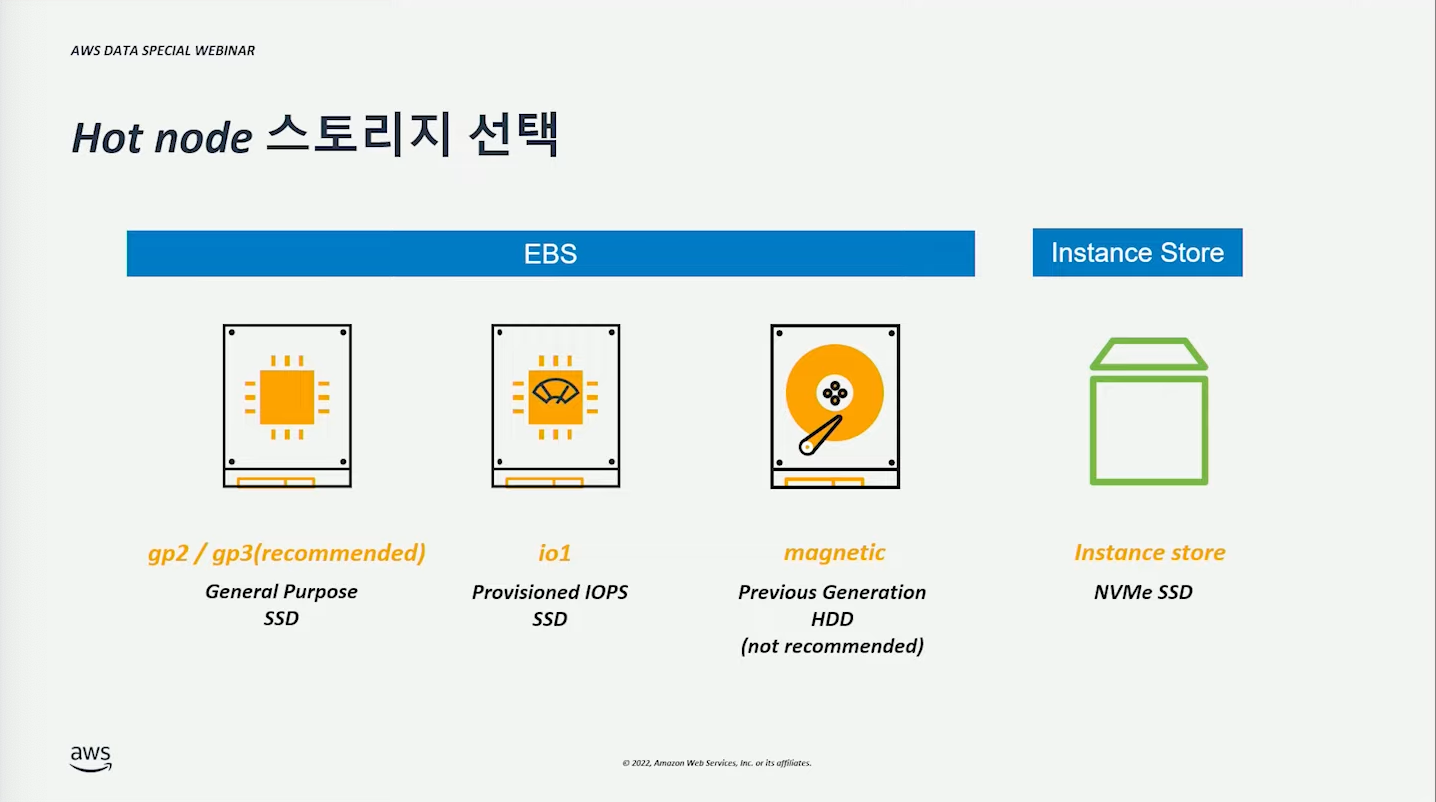
일반적인 상황에서는 gp3 를 사용하면 될 것이다.
빠른 I/O 처리가 필요한 경우에는 NVMe SSD 를 사용할 수 있다.
Domain 구성 예측 5 - Master Node #

데이터 노드와 같은 아키텍쳐(graviton or intel)인 인스턴스 타입을 사용해야한다.
위 권장 타입은 최소한의 상황에 대한 타입이므로, 모니터링 후 적절한 타입을 선택해야 한다.
마스터 노드는 1개로 동작한다. n개가 필요한 이유는 단지 ‘가용성’을 위함이다.
API 요청 핸들링 (구조) #
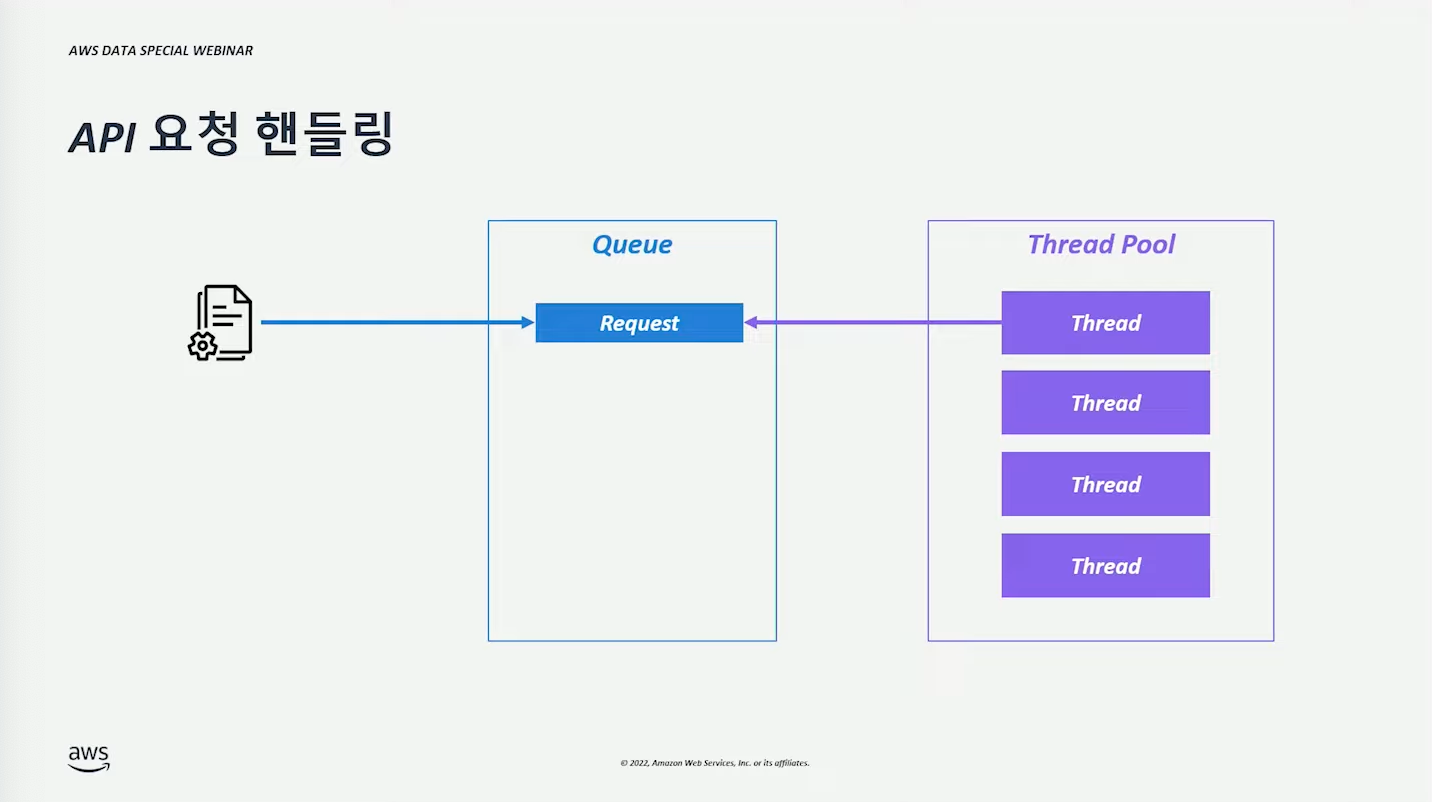
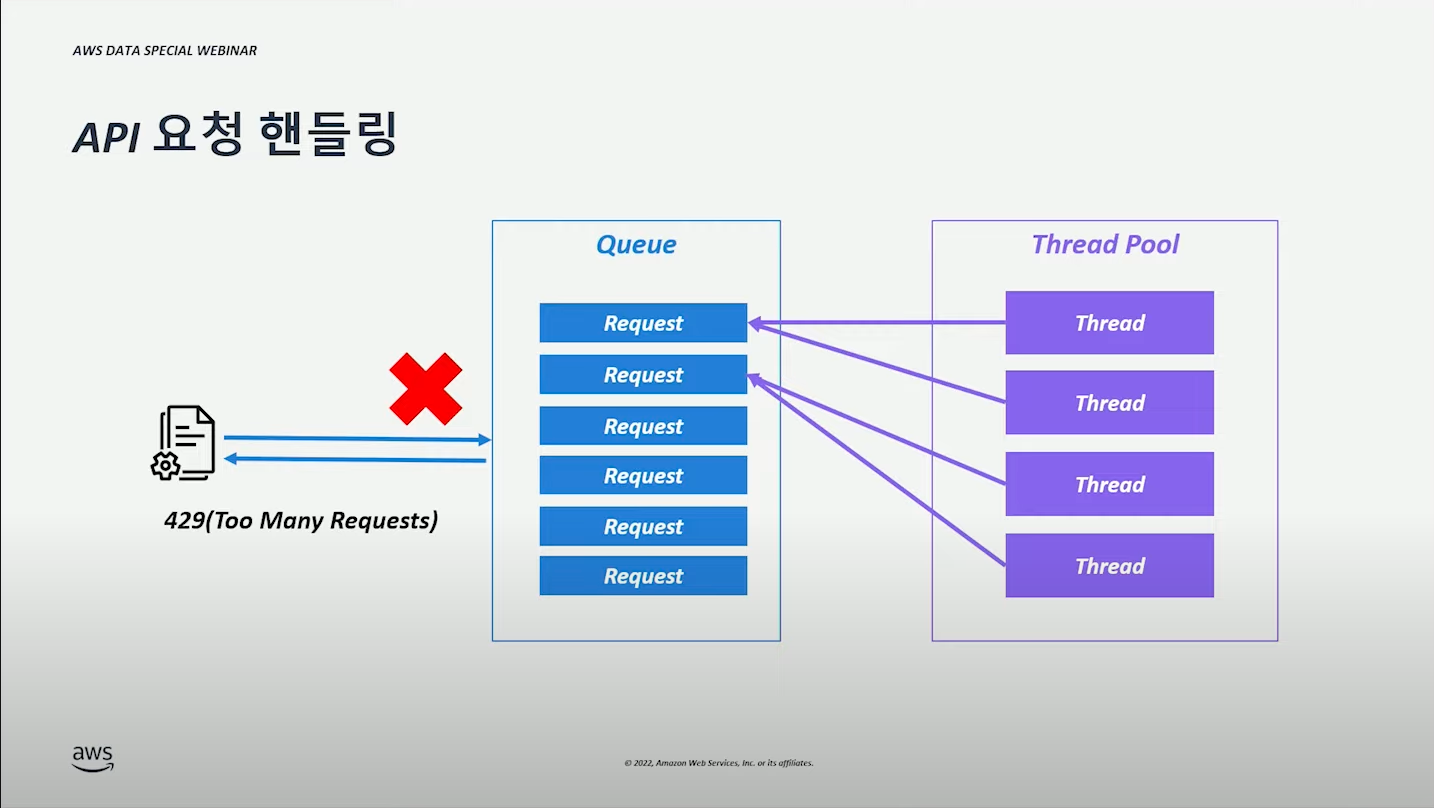
Queue 에 요청이 쌓이고, Thread Pool 의 thread 가 요청을 처리하는 구조이다.
- Thread는 샤드별로 할당된다.
- 하나의 요청에 대해 n개의 thread 가 처리한다.
Queue 에 요청이 꽉 찼다면, 429 Too Many Requests 응답된다.
Queue, Thread Pool, vCPU 상관관계 #

검색 성능 최적화 (for Read) #
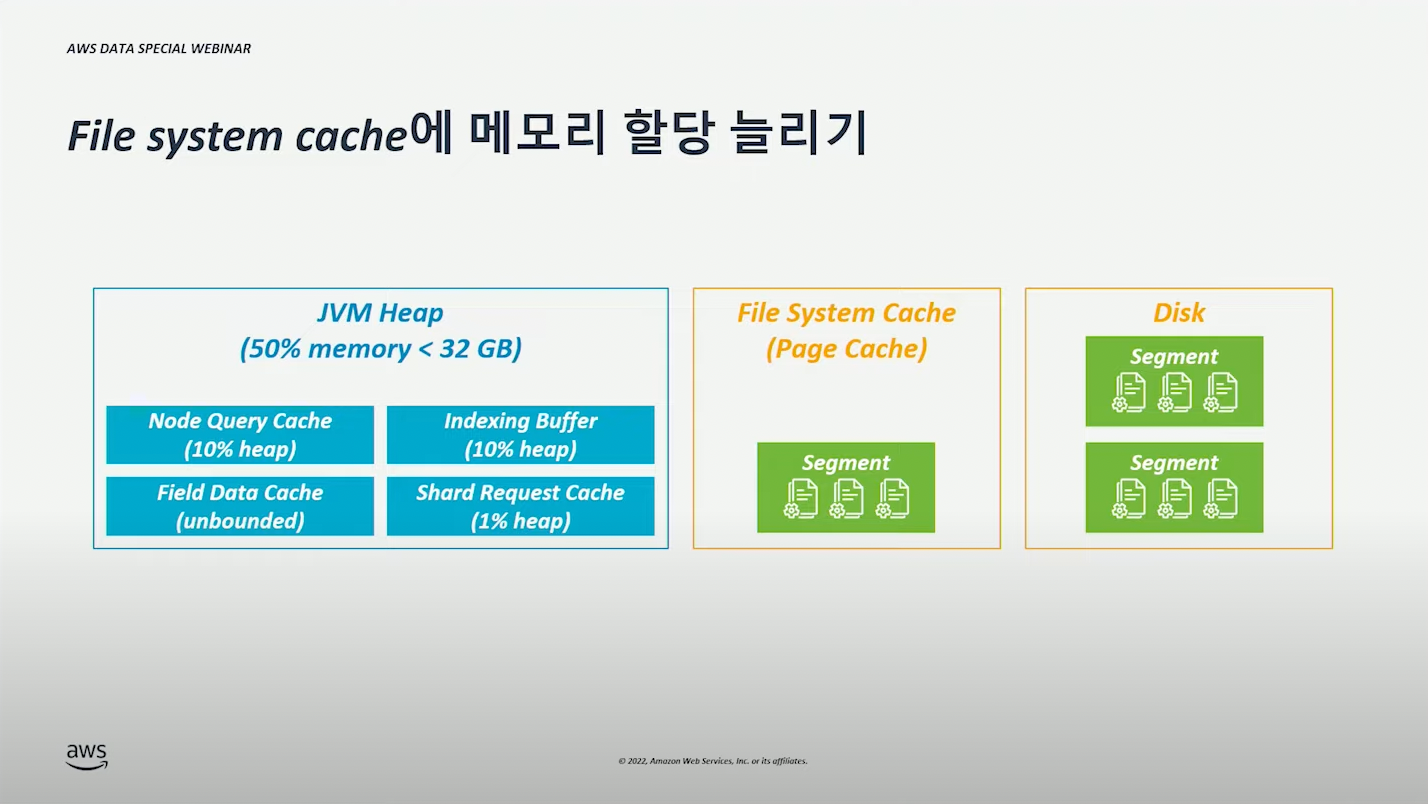
File System Cache 메모리 증설 #
File System Cache 메모리 증설하여 성능을 개선할 수 있다.
Node Query Cache 재사용 (활용) #
Filter 를 사용했을 때 응답 속도를 개선하기 위해 사용되는 캐시 (LRU)
Heap 영역의 10%를 사용한다.
Instance Store 사용 #

복잡한 Document 구조 피하기 #
1. (Nested) 중첩 필드 유형 등의 복잡한 구조는 피한다.
- 일반 필드 유형보다 검색 요청을 처리하는데 몇 배 더 오래 걸릴 수 있다.
- 중첩 유형 하위에 여러 필드가 있고, 해당 필드로 검색하는 경우 오래 걸릴 수 있다.
copy_to를 사용하여 여러 필드를 결합하고 단일 필드로 복사하여 개선할 수 있다.- 즉, n 개의 검색 조건을 주는 것보다 1 개의 필드로 만들어 단일 검색으로 쿼리하는 것을 말한다. (예를 들어, first, last field로 검색하던 것을 full field 로 만들어 검색한다.)
2. 조인 필드 유형으로 부모-자식 관계 사용하는 것을 최대한 피한다.
- 일반 필드 유형보다 검색 요청을 처리하는데 몇 배 더 오래 걸릴 수 있다.
- 1:N 부모-자식 관계 외에는 사용하지 않는 것을 권장한다.
- 조인이 필요한 경우, 인덱싱 시점에 미리 전처리하여 저장하는 것이 검색 성능에 유리하다.
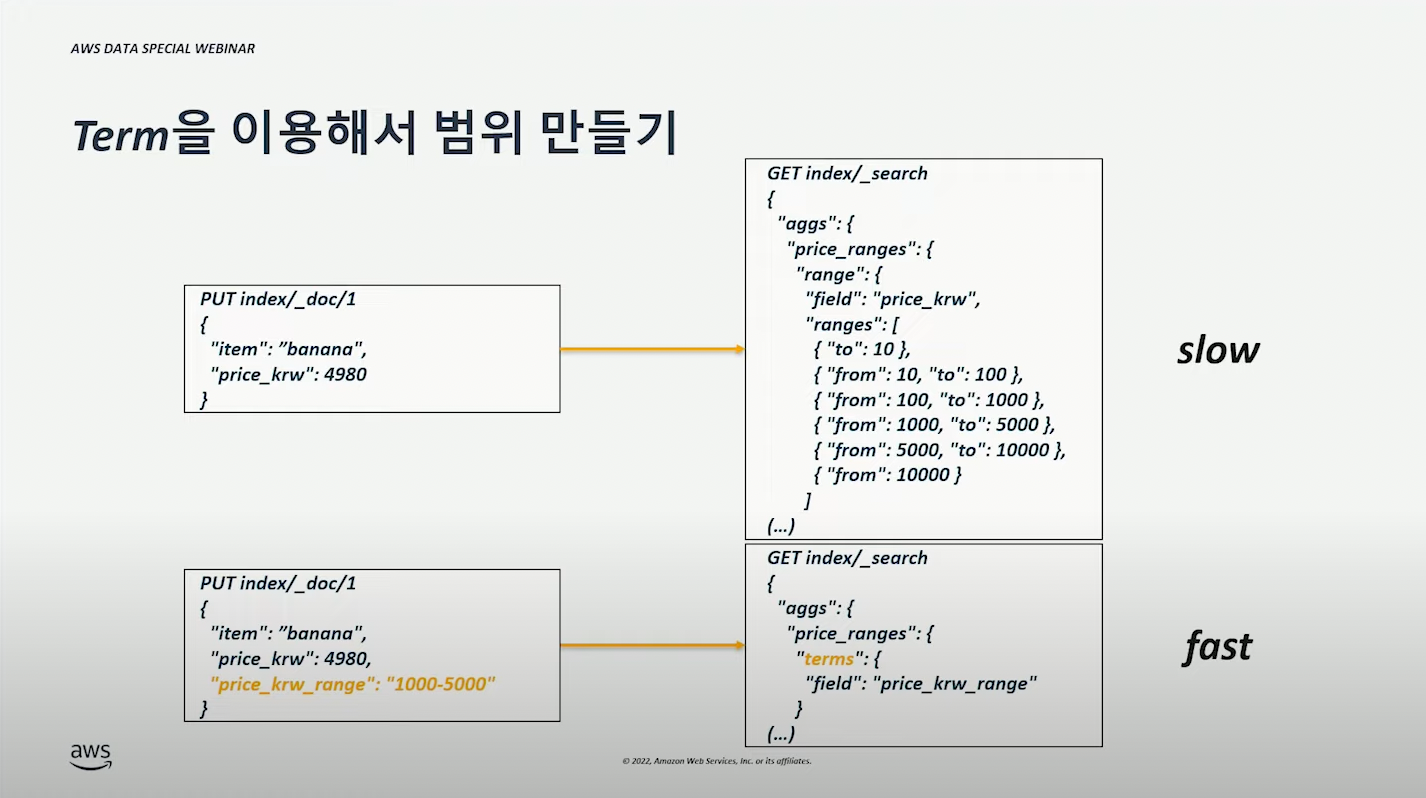
- Term 형태로 Range 를 미리 설정하는 것도 동일하다. (아래 그림 참고)
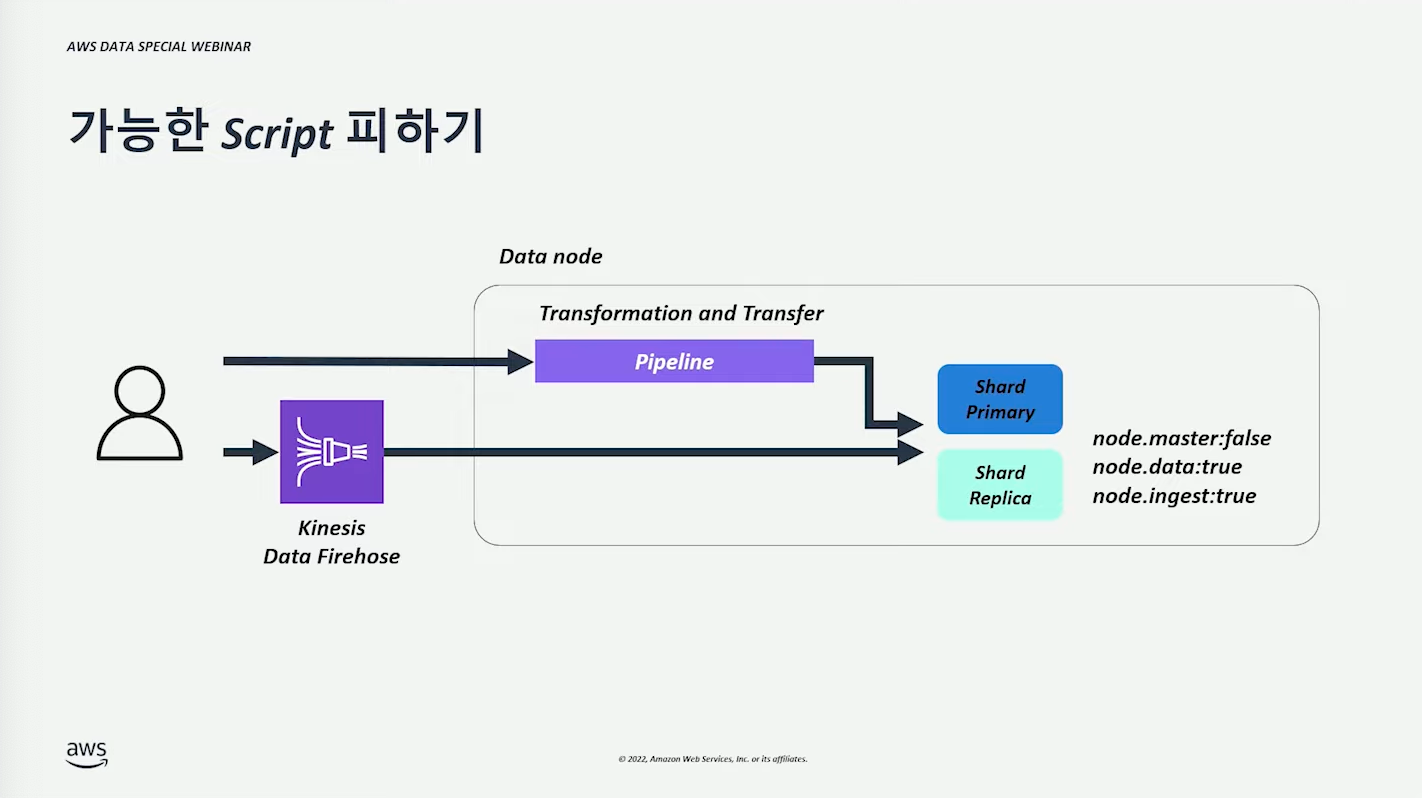
가능한 Script 피하기 #
검색 시 Script 사용하면 검색 성능이 저하된다.
미리 전처리된 데이터를 사용해야 한다.
- Kinesis, Lambda 등을 통해 전처리 후 데이터를 넣으면 이후 검색 성능 괜찮을 것이다.
Index Sorting #
정렬 사용 시 인덱스 소팅을 사용하는 것이 좋다. (설명을 들어보니 DB 인덱스와 동일한 구조)
큰 Result 는 Paging, Async 검색 활용 #
1. OpenSearch 는 단일 검색 요청에서 반환될 수 있는 Document 수에 제한이 있다.
- 기본 limit : 10,000개
2. limit 수정은 index.max_result_window 업데이트 하면 된다. (?)
- limit 을 늘릴 수 있지만, 큰 Heap 메모리가 필요하고 vCPU 사용률 증가할 수 있다.
3. search_after, size & from 함께 페이징 사용
- API 실행 당 검색되는 문서 수를 줄인다.
4. 비동기 검색 사용
- 배치 프로세싱과 같이 오랫동안 실행되는 쿼리의 경우 비동기 검색을 고려하자.
Index Roll-Up #
집계 비용을 절약할 수 있다.
집계된 결과만을 볼 때 유용하게 사용할 수 있다.
조금 더 찾아볼 것
인덱싱 성능 최적화 (for Write) #
_bulk API #
bulk API를 통해 쓰기를 최적화할 수 있다.
적절한 Payload 사이즈는 구성에 따라 다르다. 모니터링 필요하다.
단일 샤드 기준 3MB ~ 5MB 설정하고 모니터링하면 좋다고 한다.
새로고침 간격 (refresh interval) 조절 #
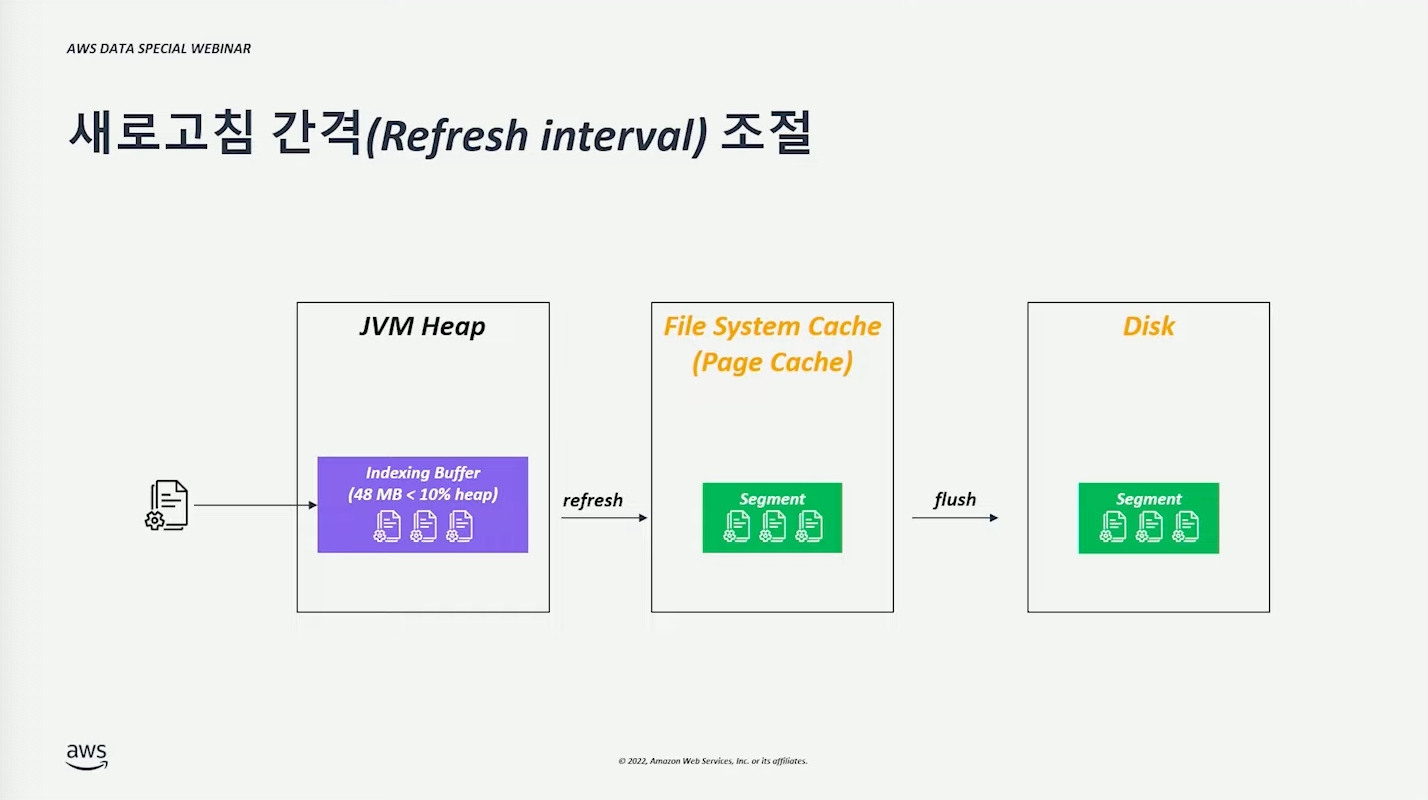
인덱싱 과정은 다음과 같다.
- 메모리 Heap 영역의 버퍼로 쓰인다.
- (refersh 거친 후) File System Cache의 세그먼트 단위로 만들어진다. 이때부터 검색이 가능한 상태가 된다.
- (flush 거친 후) Disk에 세그먼트가 저장된다.
(당연스럽게도) 세그먼트 생성 빈도를 줄이면 성능이 좋아진다. 다만 인덱싱을 늦게 함으로써 검색 가능한 시점이 늦어질 수 있다. 쓰기 ⇿ 검색 간격이 넓어도 된다면 고려할 수 있다. (tradeoff)
Replica 비활성화 #
인덱싱 관점에서는 (복제 과정이 없어지기 때문에)Replica 를 비활성화하면 처리량이 향상된다.
Replica 없이 운영하되 배치 형태로 스냅샷을 뜨거나 하면 괜찮을 수도 있다.
자동으로 생성되는 ID 사용 #
Document ID를 개발자가 지정하면, 인덱싱 과정에서 ID 충돌 검사가 들어간다.
자동으로 생성되는 ID 를 사용하게 되면, 인덱싱 과정에서 ID 충돌 검사를 건너뛰기 때문에 인덱싱 성능이 좋아진다.
인덱싱, 검색 워크로드 분리 #
하나의 Domain(= Cluster)에서 인덱싱, 검색을 동시에 수행하면 노드의 자원을 공유함으로 요청 간의 경쟁이 발생할 수 있다.
클러스터 간 (자동)복제 기능을 통해 인덱싱, 검색 워크로드를 분리할 수 있다. (= 도메인 최적화)
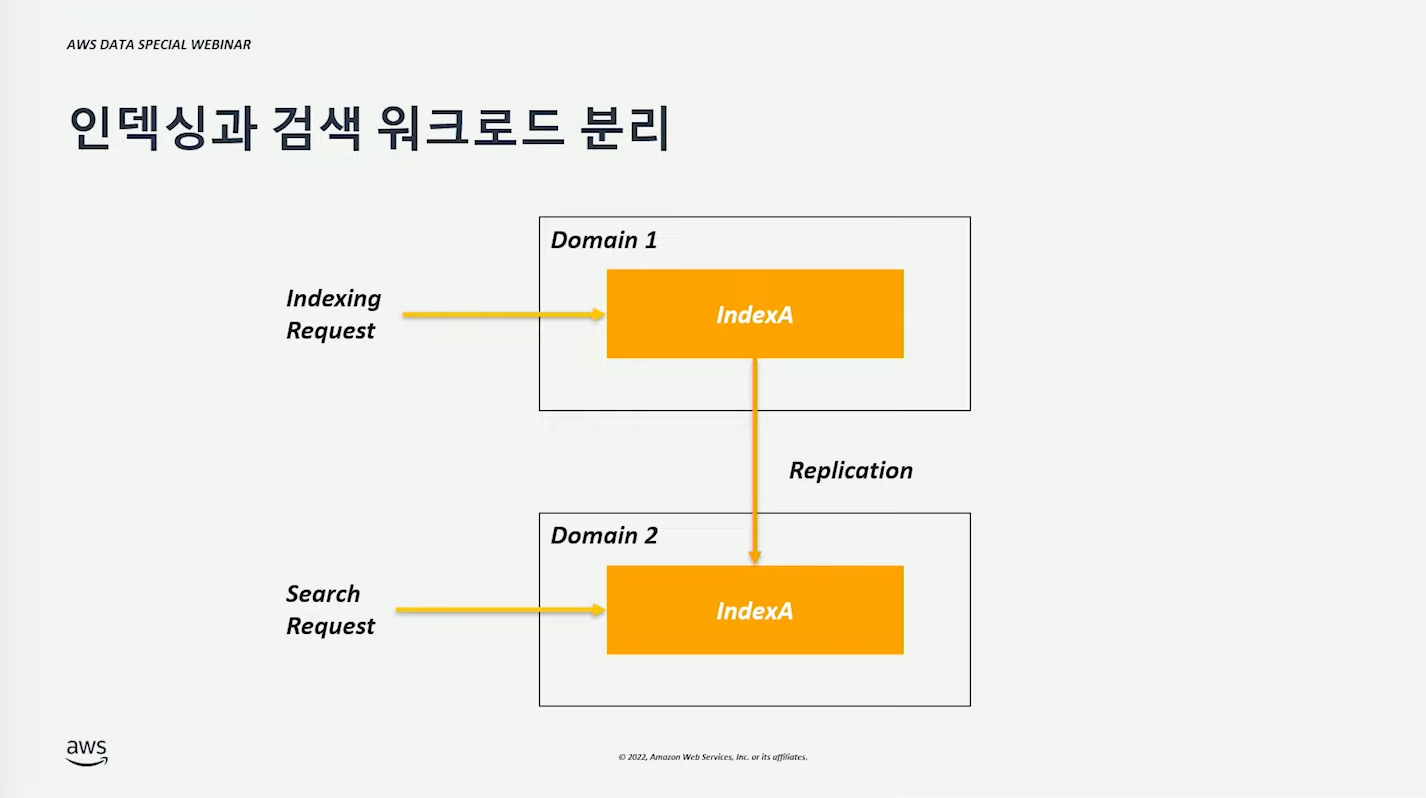
기타 유용한 팁 #
자동 튜닝(Auto-tune) 사용 #
(자동으로) 성능을 분석해주고, 최적화된 값으로 설정해준다.
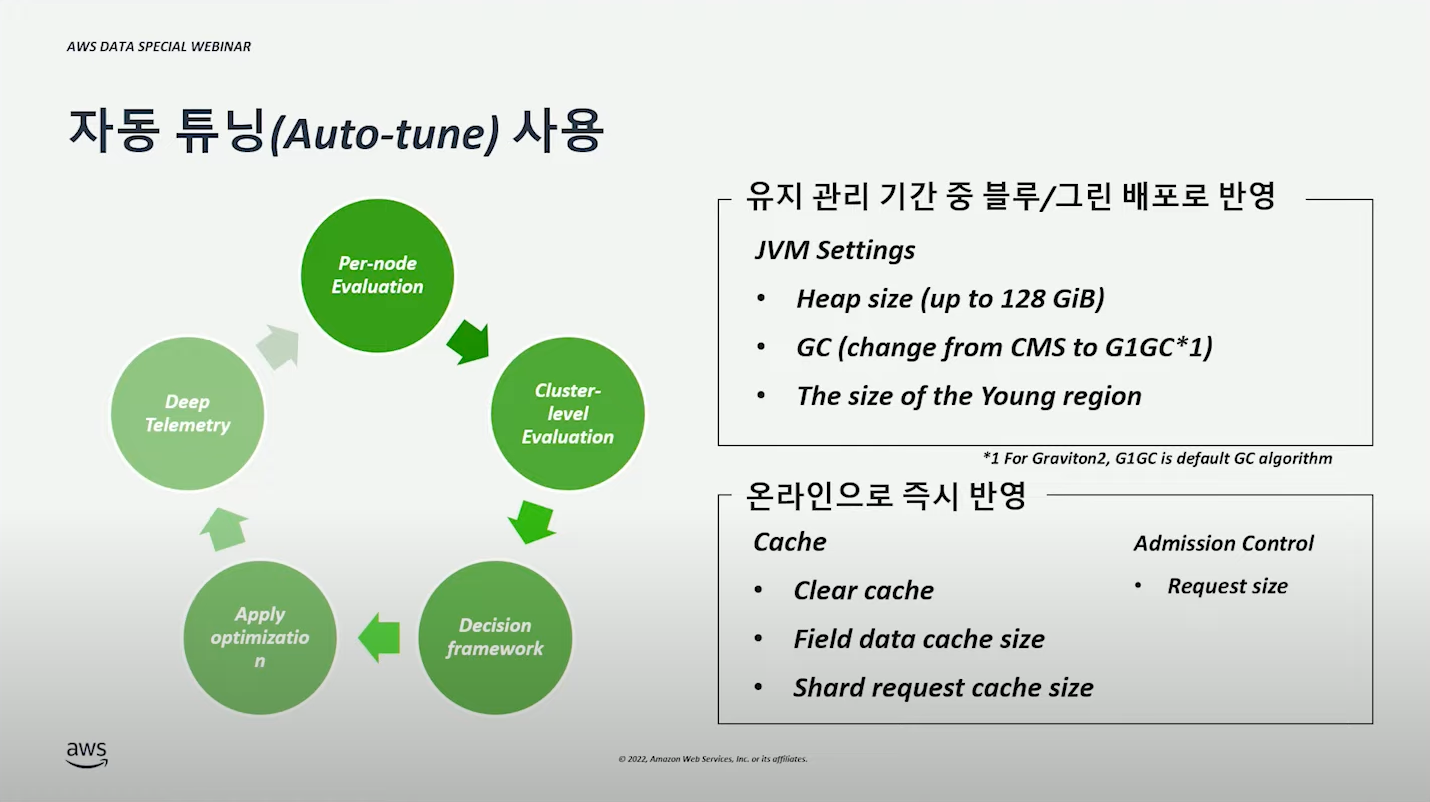
- JVM 관련 설정은 (재배포가 필요하기 때문에)Blue/Green 배포로 반영된다.
- 그 외 설정은 온라인 반영 가능하기 때문에 즉시 반영된다.
워크로드에 따른 클러스터 분리 #
같은 검색이더라도, 워크로드마다 특징이 다를 수 있다. 특징 별 최적의 리소스를 구성하여 사용할 수 있다.
- 로그 분석 : 데이터량이 많고 높은 I/O 성능이 필요하다.
- Full-Text 검색 : 데이터 량 적지만 단위시간당 검색량이 많기 때문에 vCPU/Memory 성능이 많이 필요하다.
상호(= 도메인 = 클러스터) 참조 필요시 클러스터 간 검색을 통해 한번에 검색할 수도 있다.
운영 환경에서는 T2, T3 인스턴스를 피한다. #

메모리 관련 이슈가 발생하기 쉽다.
지속적으로 vCPU의 사용량이 (많이)요구되는 경우에는 EC2에서 처럼 CPUCreditBalance 가 고갈될 수 있다. (= 원래 인스턴스가 갖고 있던 vCPU 성능으로 되돌아가는 것 (하락되는 게 아님))
인덱싱, 검색 요청 #
- 인덱싱(write) : 가장 마지막에 쓰인 인덱스에 요청한다.
- 검색 요청(read): 모든 인덱스에 요청한다.
스케일링 전략 #
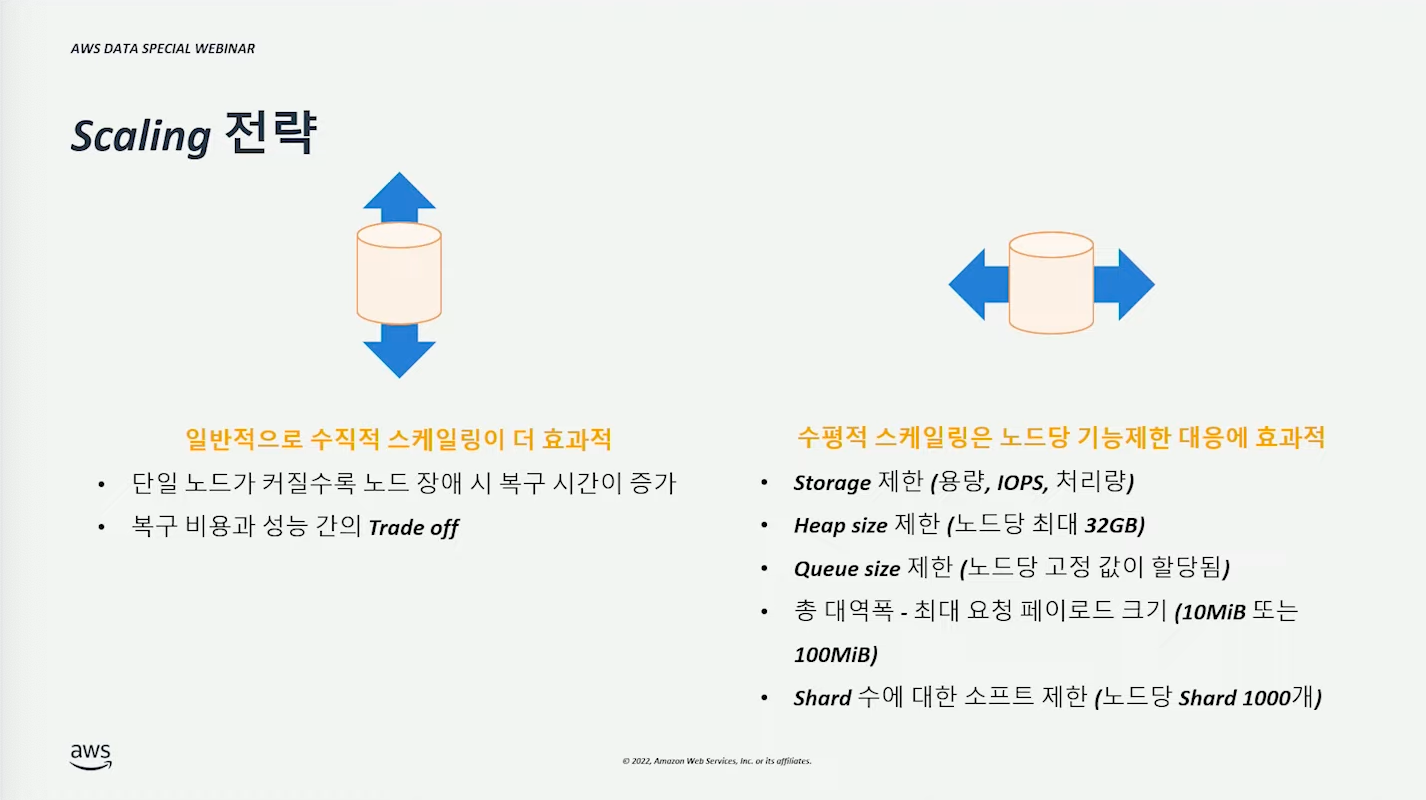
일반적으로 Scale-Up이 더 효과적이다.
Scale-Out 은 노드가 갖고 있는 제한사항 극복하거나 가용성을 위해 사용할 수 있다.