Pinpoint #
" 다양한 도구와 APM(application performance management)을 사용하고 있었으나 이것으로는 부족했다. 결국 시스템 복잡도가 높아지며 발생하는 문제를 해결하기 위해 n계층 아키텍처를 효과적으로 추적할 수 있는 새로운 플랫폼을 개발하기로 했다. “
분산 시스템에서 (1)성능을 분석하고, (2)문제를 진단, 처리하는 플랫폼이다.
다음과 같은 특징/기능이 있다.
| 특징 / 기능 | 설명 |
|---|---|
| 분산 트랜잭션 추적 | 분산 애플리케이션에서 메시지를 추적할 수 있다. |
| 애플리케이션 토폴로지 자동 발견 | 애플리케이션의 구성을 자동으로 파악할 수 있다. |
| 확장성 | 대규모 서버군을 지원할 수 있다. |
| 문제 발생 지점, 병목 구간 확인 | 코드 수준의 가시성을 제공해 문제 발생 지점과 병목 구간을 쉽게 발견할 수 있다. |
| Bytecode instrumentation 기법 | 코드를 수정하지 않고 원하는 기능을 추가할 수 있다. |
Google Dapper 스타일의 분산 트랜잭션 추적 #
Google Dapper 스타일의 추적 방식을 사용해, 분산된 요청을 트랜잭션으로 추적한다.
Google Dapper 의 분산 트랜잭션 추적 방법 #
Node 1 에서 Node 2로 메시지를 전송했을 때, Node 1 과 Node 2가 처리한 메시지의 관계를 찾아내는 것이다.
이때, (관계를 찾아내기 위해)애플리케이션 레벨에서 메시지에 (식별을 위한)태그를 추가했다.
Pinpoint 는 이 추적 방식을 변형해 호출 추적에 사용한다. 태그 데이터는 Key의 집합으로 구성되며, 이 집합을 TraceId라고 정의한다.
Pinpoint의 자료 구조 #
Pinpoint 의 핵심 자료구조는 Span, Trace, TraceId 로 이뤄져 있다.
| 자료구조 | 설명 |
|---|---|
| Span | RPC 추적을 위한 기본 단위 RPC가 도착했을 때 처리한 작업을 나타내며 추적에 필요한 데이터가 들어가 있다. 코드 수준의 가시성을 확보하기 위해 Span의 자식으로 SpanEvent 라는 자료구조를 갖고 있다. Span은 TraceId를 갖고 있다. |
| Trace | Span의 집합 연관된 RPC의 집합으로 구성된다. Span의 집합은 TransactionId가 같다. Trace는 SpanId와 ParentSpanId를 통해 트리 구조로 정렬된다. |
| TraceId | TransactionId, SpanId, ParentId 로 이뤄진 키의 집합 TransactionId 는 메시지의 아이디, SpanId, ParentId 는 RPC의 부모 자식 관계를 나타낸다. |
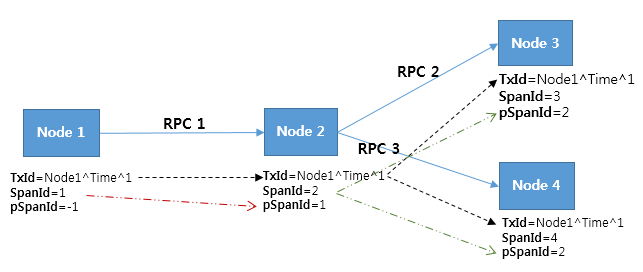
위 그림에서 TxId(TransactionId)는 3개의 RPC가 하나의 연관된 트랜잭션이라는 것을 표현한다. 하지만 TxId만으로는 각 RPC 간의 관계를 정렬할 수 없다. (즉 뭐가 먼저고, 뭐가 나중인지 알 수 없다.)
RCP 간의 정렬을 위해 SpanId와 ParentSpanId가 사용된다.
Pinpoint 는 TxId를 통해 연관된 N개의 Span을 찾아낼 수 있다. SpanId, ParentSpanId로 N개의 Span을 트리로 정렬할 수 있다.
SpanId, ParentSpanId 는 (1)64bit long 형 정수이다. (2)임의로 생성되는 값이라 충돌할 수 있지만 (64비트라)확률은 낮다. (3)키가 충돌했을 때, Google Dapper와 Pinpoint 는 충돌을 해결하지 않고 충돌 여부를 알려주는 방법을 사용한다.
TransactionId는 AgentId, JVM 시작시간, SequenceNumber 로 구성된다.
AgentId : JVM 실행 시 사용자가 임의로 정하는 ID, AgnetId는 Pinpoint가 설치되는 전체 서버군에서 중복되는 것이 없어야 한다. AgentId의 유일성을 보장하는 쉬운 방법은 호스트 이름($HOSTNAME)을 사용하는 것이다. 서버 안에 JVM을 여러 개 기동해야 한다면, 호스트 이름에 접미어(postfix)를 추가해 아이디 중복을 피할 수 있다.
JVM 시작 시간 : 0부터 시작하는 SequenceNumber의 유일성을 보장하기 위해 JVM의 시작시간이 필요하다. 이 값은 사용자의 실수로 동일한 AgentId가 설정됐을 경우 ID의 충돌 확률을 줄이는 역할도 한다.
SequenceNumber : Pinpoint Agent가 내부적으로 발급하는 ID, 0부터 순차적으로 증가하는 값이다. 개별 메시지마다 발급한다.
Google Dapper나 Twitter의 분산 트랜잭션 추적 플랫폼인 Zipkin은 TraceId를 임의로 발급하고, 이 키가 충돌하는 것은 자연스러운 상황으로 판단한다. 그러나 Pinpoint 에서는 TransactionId의 충돌 확률을 낮추고 싶었기에 위와 같이 구성했다.
데이터의 양은 적지만 충돌 확률이 높은 방식과 데이터의 양은 많지만 충돌 확률이 낮은 방식 중에서 후자를 선택한 것이다.
” Pinpoint보다 더 좋은 방식도 존재할 수 있다. TransactionId 구현 후보에는 중앙 키 서버에서 키를 발급하는 방식도 있었다. 이렇게 중앙 서버에서 키를 발급하면 성능 문제와 네트워크 오류 문제가 있을 수 있어 벌크 형태로 발급받는 것까지 고려했다. 나중에 이러한 방식으로 변경할 수도 있지만 현재는 단순한 방식을 채택했다. Pinpoint는 TransactionId를 충분히 변경할 수 있는 데이터로 판단하고 있다. “
Bytecode instrumentation #
위에서 언급한 ‘분산 트랜잭션 추적’을 구현하기 위해, 개발자가 직접 코드를 수정하는 방법이 있다. 개발자가 RPC 호출 시 태그 정보를 직접 추가하도록 개발하는 것이다.
하지만 분산 트랜잭션 추적이 좋은 기능이라고 해도, 이를 위해 코드를 수정하는 것은 부담스러운 일이다.
Twitter의 Zipkin은 수정된 라이브러리와 자체 컨테이너(Finagle)를 사용해 분산 트랜잭션 추적 기능을 제공한다. 하지만 필요하면 코드도 수정해야 한다.
Pinpoint는 코드를 수정하지 않고도 분산 트랜잭션 추적 기능을 제공하길 원했고 코드 수준의 가시성을 원했다. 이 문제를 해결하기 위해 bytecode instrumentation 기법을 도입했다. Pinpoint agent는 RPC 호출 코드를 가로채 태그 정보를 자동으로 처리한다.
Bytecode instrumentation의 단점 극복 #
Bytecode instrumentation은 수동 방식(라이브러리), 자동 방식 중에서 자동 방식에 해당한다.
| 방식 | 설명 | 장점 | 단점 |
|---|---|---|---|
| 수동 방식 | Pinpoint가 API를 제공하고 개발자는 Pinpoint의 API를 사용해 (중요한 지점에 데이터를 추적할 수 있는)코드를 개발한다. | - API가 단순하다. 이에 따라 버그 발생 가능성이 낮다. | - 사용자가 코드를 수정해야 한다. - 추적 수준이 낮다. |
| 자동 방식 | Pinpoint가 라이브러리의 어떤 API를 가로챌지 결정해 코드를 개발한다. 이를 통해 개발자가 개입하지 않아도 자동으로 기능이 적용되게 한다. | - 사용자가 코드를 수정하지 않아도 된다. - 바이트 코드의 정보가 많기 때문에 정밀한 데이터를 수집할 수 있다. | - 추적할 라이브러리 코드를 순간적으로 파악해 추적 지점을 판단할 수 있는 수준 높은 개발자가 필요하다. - 난이도가 높은 개발 방법인 bytecode instrumentation을 사용하므로 버그 발생 가능성이 높다. |
당장에는 수동 방식의 비용이 낮을 수 있지만, 많은 클라이언트가 사용한다고 가정하면 자동 방식의 비용이 더 낮다는 결론이다.
Bytecode instrumentation 숨은 가치 #
Bytecode instrumentation는 위의 비용 측면 외에도 더 많은 가치를 제공한다.
1. API를 노출하지 않는다.
API를 노출해 제공하면, 이후 API를 쉽게 변경할 수 없다는 제약이 생긴다. (이 제약은 API 제공자에게는 스트레스이다.)
Bytecode instrumentation를 사용하면 API를 사용자에게 노출하지 않아도 되므로 API 의존성 문제를 해소할 수 있다.
” 이를 반대로 생각하면, Pinpoint를 수정해 사용하려는 개발자의 입장에서는 내부 API 변경이 자주 발생할 것이라는 의미이기도 하다. “
2. 손쉬운 적용과 해제
Bytecode instrumentation은 라이브러리의 프로파일링 코드나 Pinpoint 자체에 문제가 생겼을 때 애플리케이션에 영향을 준다는 단점이 있다. 하지만 코드를 변경할 필요가 없으므로 Pinpoint를 쉽게 적용하고 해제할 수 있다.
JVM 구동 시 JVM 시작 스크립트에 다음과 같은 Pinpoint Agent 설정 3개를 추가하면 쉽게 Pinpoint를 적용할 수 있다.
> javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar
> Dpinpoint.agentId=
> Dpinpoint.applicationName=<동일 서비스임을 나타내는 이름(AgentId의 집합)>
Pinpoint 때문에 문제가 발생했다면 JVM 시작 스크립트에서 Pinpoint Agent 설정을 제거해 Pinpoint 적용을 해제하면 된다.
Bytecode instrumentation의 작동 방법 #
Bytecode instrumentation 기술은 Java 바이트 코드를 다루므르 위험하고 생산성이 낮으며, 개발자가 실수하기 쉽다.
Pinpoint는 인터셉터로 추상화해 생산성과 접근성을 높였다.
Pinpoint는 클래스 로드 시점에 애플리케이션 코드를 가로채 성능 정보와 분산 트랜잭션 추적에 필요한 코드를 주입한다. 애플리케이션 코드에 직접 추적 코드가 주입되므로 성능이 좋다.
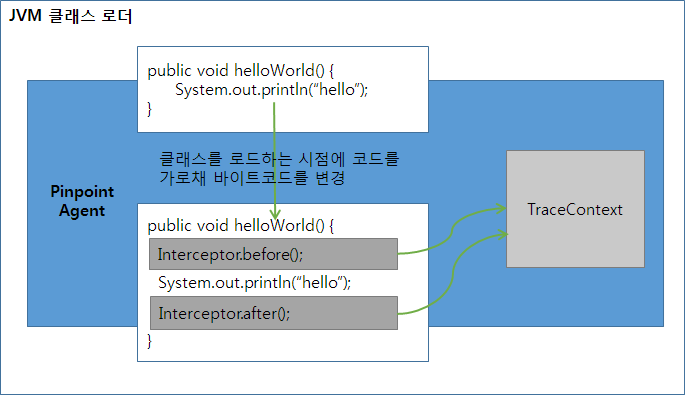
Pinpoint는 API 인터셉터 부분과 성능 데이터 기록 부분을 분리했다.
추적 대상 메서드에 인터셉터를 주입해 앞 뒤로 before(), after() 메서드를 호출하게 하고 before(), after() 메서드에 성능 데이터를 기록하는 부분을 구현했다.
Pinpoint Agent는 bytecode instrumentation을 통해 필요한 메서드의 데이터만 기록하므로 생성되는 프로파일링 데이터의 크기가 작다. (— ?)
‘Pinpoint Agent의 성능 최적화’ 부분은 해당 포스트 글을 다시 읽어본다.
키워드:
- Thrift
- 가변 길이 인코딩을 통한 최적화된 데이터 기록 (⇿ 고정 길이 인코딩)
- 상수 테이블 사용 (반복되는 API 정보, SQL, 문자열을 상수로 치환하여 사용)
- 대량의 요청은 샘플링 처리
- UDP
- 비동기 데이터 전송
참고: