우아한 테크 세미나 : 우아한 Redis (2019) #
이번 세미나에서 다루지 않는 것들
- Redis Persistence(RDB, AOF)
- Redis Pub/Sub
- Redis Stream
- 확률적 자료구조
- Hyperlog
- Redis Module
Redis 소개 #
- In-Memory 데이터 저장소
- Open Source (BSD 3 License)
- 지원하는 자료구조
- String
- Set
- Sorted-Set
- Hash
- List
- Hyperloglog
- Bitmap
- Geospatial index
- Stream
- Only 1 Commiter
Cache 란? #
결과를 미리 저장해두었다가 빠르게 제공하는 것
- ex : (dp) factorial
Disk
Memory
L3 cache
L2 cache
L1 cache
core
Cache 아키텍처 #1 : Look-Aside Cache #
Client - Server - DB
ㄴ Cache
- 캐시를 먼저 조회한다.
- 캐시에 데이터가 있다면 캐시에서 응답한다.
- DB를 조회한다.
- 응답한다.
- DB 조회/응답하면서 캐시에 내용을 저장한다.
Cache 아키텍처 #2 : Write-Back Cache #
Client - Server - DB
ㄴ Cache
- 서버는 ‘캐시’에만 데이터 저장(+조회)한다.
- 캐시에는 데이터가 저장된다.
- 메모리 용량이 한계가 있으니 특정 시간(주기) 동안 저장한다고 볼 수 있다. (DB에 저장하고 삭제한다.)
- 캐시에는 데이터가 저장된다.
- (특정 시간마다)캐시의 데이터를 DB에 저장한다.
- DB에 저장한 내용은 캐시(메모리)에서 삭제한다.
특징
- 데이터가 유실될 수 있다.
- 메모리 -> DB로 데이터를 저장하기 전에 문제가 생긴다면
- Log를 DB에 저장하는 경우 Write-Back 을 활용하기도 한다.
왜 Collection 이 중요할까? #
Redis 는 Memcached 와 많이 비교된다.
Memcached 에는 Collection 을 제공하지 않는다.
- 개발의 편의성
- 개발의 난이도
Redis 에서는 Collection 기능을 처리/제공하기 때문에 개발을 편리하고, 쉽게 해준다.
데이터 자료구조를 잘 선택해야 한다.
예시 1 : 랭킹 서버를 구현한다면? #
방법 1 : DB 에 score 저장, order by 조회
데이터가 많아지면, latency가 증가될 수 있다. (결국 disk를 사용하니까)
방법 2 : Redis sorted-set 활용
예시 2 : 친구 리스트 관리 기능을 구현한다면? #
연결 리스트로 데이터를 관리하여 구현할 것이다.
[예시]
(A, B, C 라는 사람이 있을 때)
A List 에 B, C 를 저장
방법 1 : DB로 구현한다.
동시성 문제에 직면할 수 있다.
(동시에 B, C 를 저장할 때 둘 중 하나의 데이터만 저장될 수 있다.)
방법 2 : Redis로 구현한다.
(싱글 스레드 기반)Redis 의 자료구조는 Atomic 하다.
Race Condition 을 피할 수 있다.
Redis 활용 예시 #
1. Remote Data Store (공유 캐시 저장소)
2. 인증 토큰 (string, hash, …)
3. Ranking 보드 (sorted set)
4. 사용자 API Limit
5. Job Queue(list)
Redis Collections #
- string
- list
- 중간에 데이터를 삽입해야하면 리스트를 사용하는 것을 다시 고려해봐야 한다.
- set
- 중복된 데이터를 저장하지 않아야 할 때
- sorted-set
- set + 순서를 보장한다.
- hash
string #
set <key> <value>
mset <key1> <value1> <key2> <value2> ...
get <key>
mget <key1> <key2> <key3> ...
고민 포인트
- Key 를 어떤 것으로 설정할 것인지?
- Key 에 따라 데이터의 분산(?)이 달라질 수 있다.
list #
lpush <key> <value>
rpush <key> <value>
lpop <key>
rpop <key>
blpop <key>
brpop <key>
(데이터를 push 하기 전까지 대기)
고민 포인트
활용 : 리스트에 넣어놓고 앞에서 부터 하나씩 가져갈 때 (Job Queue) 등등
set #
sadd <key> <value> : value 가 이미 key에 있으면 추가되지 않는다.
smembers <key> : 모든 value 를 돌려준다.
sismember <key> <value> : value 가 존재하면 1, 없으면 0
활용 : 특정 유저를 Follow 하는 목록을 저장 (즉, 유니크한 관리가 필요할 때)
sorted-set #
가장 많이 활용되는 것 중 하나
zadd <key> <score> <value> : value 가 이미 key에 있으면 score 가 overwrite 된다.
zrange <key> <startIndex> <endIndex>
zrevrange <key> <startIndex> <endIndex>
zrange testkey 0 -1 : 모든 범위를 다 가져옴
특징
score: double 타입(실수형)이다.(정수형 X)- 실수형이기 때문에 표현할 수 없는 정수 값들이 있다.
- 따라서, score 를 사용할 때 주의해야한다.
- 실제로 자바스크립트에서 (js 아닌)서버쪽으로 데이터를 보낼 때, 숫자 값들을
string으로 보내곤한다.
활용 : 사용자 랭킹 보드
hash #
key 밑에 sub key 가 존재한다.
hmset <key> <subkey1> <value1> <subkey2> <value2> ...
hgetall <key>
hget <key> <subkey>
hmget <key> <subkey1> <subkey2> ...
Collection 주의 사항 #
- 하나의 컬렉션에 너무 많은 아이템(x만개, xx만개, …)을 담으면 좋지 않다.
- 1만개 이하의 몇 천개 수준으로 유지하는게 좋다.
- Expire는 Collection 의 원소(item 개별)별로 걸리지 않고, 전체 Collection(key 별로?)에 대해서만 걸린다.
- 10000개의 아이템을 가진 Collection에 Expire 가 걸려있다면, expire 시간 후에 10000개의 아이템 모두 삭제
Redis 운영 #
1. 메모리 관리를 잘하자.
2. O(N) 관련 명령어는 주의하자.
3. Replication
4. 권장 설정 Tip
메모리 관리를 잘하자. #
메모리 관리가 매우 중요하다.
물리 메모리 이상을 사용하면 문제가 발생한다.
- Swap이 있다면 Swap 사용으로 해당 메모리 Page 접근 시마다 늦어진다.
- 성능이 확 떨어질 것이다. (= Disk를 사용하는 것)
- 더 이상 In-Memory 의 이점이 없다.
- Swap이 없다면, OOM 등으로 죽을 수 있다.
- Maxmemory 를 설정하더라도 이보다 더 사용할 가능성이 있다.
- maxmemory는 memory 에 제한을 거는 건데, 이것보다 더 사용할 수 있다.
- memory allocator(ex : jemalloc, …) 의 구현에 따라 디테일이 달라질 수 있다.
- 이 부분은 좀 더 찾아보자.
많은 곳에서 현재 Swap을 쓰고 있다는 사실 조차 모를 때가 많다.
- Redis 장비에 대한 메모리 모니터링이 꼭 필요하다.
- 메모리 파편화가 발생할 수 있다.
- 다양한 사이즈를 갖는 데이터 보다는 유사한 사이즈의 데이터를 저장하는 것이 유리하다.
큰 메모리를 사용하는 instance 하나보다, 작은 메모리로 여러 instance를 사용하는 것이 안전하다.
- 24GB instance < 8GB instance (x3)
Redis 필연적으로 fork 를 하게된다.
- read 가 많은 것은 크게 상관 없다.
- write 가 많은 것은 최대 메모리를 2배까지 사용할 수 있다.
메모리가 부족할 때는? #
1. Scale-Up
- 메모리가 빡빡하면 migration 중에 문제가 발생할 수도 있다.
2. 있는 데이터 줄이기
- 데이터를 일정 수준에서만 사용하도록 특정데이터를 줄인다.
- 다만 이미 swap을 사용중이라면, 프로세스를 재시작해야한다.
3. 기본적으로 Collection 들은 다음과 같은 자료구조를 사용한다.
- Hash -> HashTable 을 하나 더 사용한다.
- Sorted-Set -> Skiplist, HashTable 을 사용한다.
- Set -> HashTable 을 사용한다.
- 해당 자료구조들은 (우리가 생각하는 것 보다)메모리를 많이 사용한다.
4. Ziplist 를 이용한다.
- 속도는 약간 느려질 수 있는데, 메모리는 적게 사용할 수 있다.
- hash, sorted-set, set 을 사용하는데, 내부적으로 ziplist 를 사용하도록 변경하는 느낌
Ziplist 구조 #
찾아볼 것
선형으로 데이터를 저장한다.
In-Memory 특성 상, 적은 개수라면 선형 탐색(O(n))을 하더라도 빠르다. (그래서 Ziplist 를 써도 되는 거다.)
zlbytes|zltail|zllen|entry|entry|...|entry|zlend
List, hash, sorted-set 등을 ziplist 로 대체해서 처리하는 설정이 존재한다.
- hash-max-ziplist-entries
- hash-max-ziplist-value
- list-max-ziplist-size
- list-max-ziplist-value
- zset-max-ziplist-entries
- zset-max-ziplist-value
- …
ㄴ 데이터 몇개 까지는 ziplist를 사용하겠다는 설정 등을 할 수 있다.
ㄴ 이걸 넘어가면 원래 자료구조로 바뀌는 느낌
쓰는 것과 안쓰는 것이 메모리 사용량 20~30% 정도 차이가 난다고 한다.
O(n) 명령어를 주의한다. #
Redis = Single Thread
- 동시에 한 개의 명령어를 처리할 수 있다.
- 단순한 get/set 의 경우, 초당 10만 TPS 이상 처리 가능하다.
- 하나의 명령어가 1초가 걸렸다면 초당 TPS 가 1로 떨어질 수 있다.
- CPU 속도에 영향을 받을 수 있다.
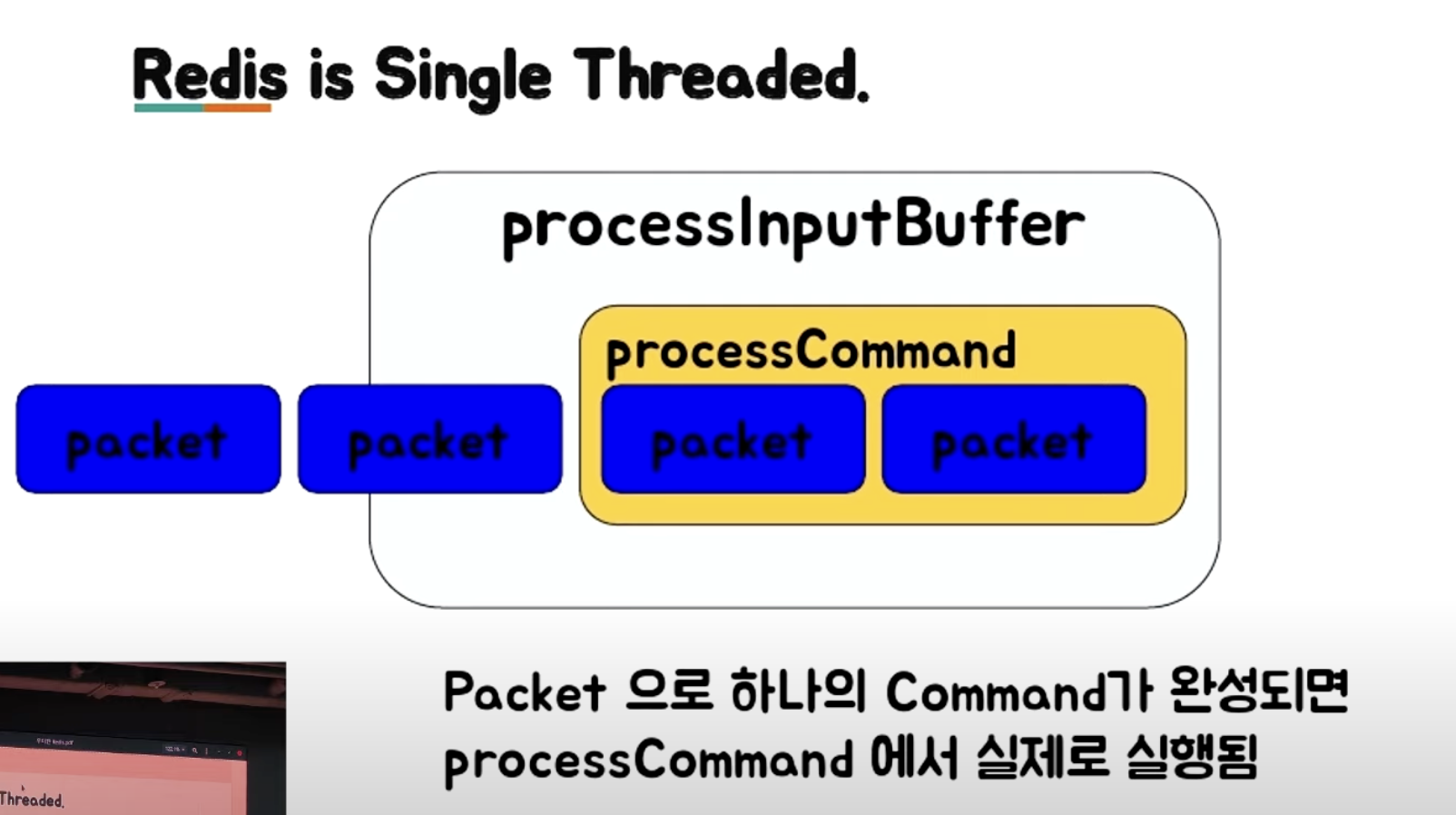
processInputBuffre 에 packet 이 들어온다. (packet 은 분리되어 들어올 수 있기 때문에 우선 packet 을 받는다.)
packaet 을 받아서, processCommand (하나의 명령어) 가 완성이 되면 실행한다.
처리 시간이 긴 명령어(O(n))를 사용하면 안된다.
- keys (all)
- scan (cursor) 으로 대체할 수 있다.
- flushall, flushdb
- 이거는 꼭 필요한 경우가 있긴 하니까, 그때만 주의해서 쓰자
- delete collections
- 원소가 n만개 있는 것을 지운다면…
- get all collections
- 원소가 n만개 있는 것을 조회한다면… (특히 매번 조회한다면…)
- Collection 을 일부만 가져온다. (sorted-set 의 경우 가능)
- Collection 을 작게 관리한다.(작은 collection 으로 관리한다.)
- 한 키당 몇천개 안쪽으로 저장하는게 좋다.
(예전) Spring Security Oauth RedisTokenStore
이전 : List (O(n)) 자료구조 사용
현재 : Set (O(1)) 자료구조 사용
Redis Replication #
- Async Replication
- Replication Lag 이 발생할 수 있다.
- Lag 이 커지면, master-slave 커넥션 끊어버리고 다시 연결한다. (이때 부하가..)
replicaof(> = 5.0.0) /slaveof명령으로 설정 가능- Replicaof hostname port
- DBMS 의 statement replication 이 유사
- 즉, 쿼리가 보내지는 것
- 이때 now 같은 명령어가 들어있으면 (primary, secondary에서)다르게 저장될 수 있다.
- 경우에 따라 다른 값이 저장될 수 있다는 것을 인지하자. (Lua script 같은 거?)
- <-> row replication X
Replication 동작 과정 #
- Priamry -> Secondary replicaof (or slaveof) 명령 전달
- Secondary 는 Primary 에 sync 명령어 전달
- Primary 는 현재 메모리 상태를 저장하기 위해 Fork
- 이 부분이 좀 문젠데, 현재 어쩔 수 없음
- Fork 한 프로세스는 현재 메모리 정보를 Disk 에 dump
- 해당 정보를 secondary 에 전달
- fork 이후의 데이터를 secondary 에 계속 전달
찾아볼 것
Replication 주의사항 #
- Replication 과정에서 fork 발생 -> 메모리 부족 발생할 수 있음
redis-cli --rdb명령 : 현재 상태의 메모리 스냅샷을 가져온다.- fork 와 같은 문제
- aws, 혹은 클라우드의 redis 는 좀 다르게 구현되어서 위 부분(vanila redis)들이 좀 더 안정적이다.
- fork 없이 replication 하기도 한다.
- 다만 속도가 좀 더 느릴 수 있다.
- 많은 대수의 redis 서버가 replica를 두고 있다면, 네트워크 이슈(대역폭)가 발생할 수 있다.
- 같은 네트워크 안에서 30GB를 사용하는 Redis Master 100대 정도가 replication 을 동시제 재시작 하면… (네트워크에 의해 끊어지고 다시 연결하고 끊어지고 다시 연결되고 등등…) 다양한 문제가 발생할 수 있다.
Redis 권장 설정 Tip #
- MaxClient 설정 : 50000
- MaxClient 만큼만 네트워크로 접속 가능하다. (값을 높여주는 것이 중요하다. 낮으면 연결 안되니까)
- RDB/AOF 설정 : OFF
- 성능상 유리
- 안정성 유리
- 보통 실무에서는 rdb/aof 설정 다 끈다.
- 혹시 필요하면 secondary 만 설정한다.
- primary 는 무조건 끈다.
- 특정 커맨드 disable
- keys
- (aws)elasticcache 는 이미 하고 있다.
- 적절한 ziplist 설정
전체 장애의 90%~99% 이상이 keys, save(rdb/aof) 사용(설정)에 의해 발생한다.
save 설정이란?
n 분마다 n 개 write 되었으면, rdb 에 저장해라! 라는 설정
Redis 데이터 분산 #
데이터의 특성에 따라, 선택할 수 있는 방법이 달라진다.
- Cache 일 때는 우아한 Redis
- Persistent 해야한다면, 우아하지 않은 Redis
1. Application
- Consistent Hashing
- twemproxy를 사용하는 방법으로 쉽게 사용 가능
- Sharding
2. Redis Cluster
Consistent Hasing #
단순 Mod 연산으로 인한 ‘데이터 분배’는 서버 추가/감소 시 리밸런싱이 너무 많이 일어날 수 있다.
(ex: 50% 이상의 데이터가 리밸런싱)
- 키(A)에 해싱 함수를 연산한다. — A’
- 이때 서버마다 기준 값이 있다.
- 키(A)는 A’ 값보다 크되, 가장 가까운 서버를 찾아간다.
- 서버가 감소되었을 때 : 리밸런싱되는 데이터는, ‘그 서버에 해당되는 데이터’ 만 리밸런싱 된다.
리밸런싱의 비율이 mod 연산보다 적다.
Sharding #
- 데이터를 어떻게 나눌 것인가?
= 데이터를 어떻게 찾을 것인가?
하나의 데이터를 모든 서버에서 찾는다면
- 모든 서버에 부하를 일으키고
- 낮은 레이턴시
Range Sharding
특정 Range 를 정의하고, 해당 Range 에 속하면 그곳에 저장/조회
- Server 1 : 1~1000
- Server 2 : 1001~2000
=> Key(1500)은 Server 2 에 저장/조회한다.
- Hot Key (Famous key) 에 의한 문제가 발생할 수 있다.
- 특정 서버만 너무 놀거나 꽉 찰 수 있다.
Modular Sharding
서버를 x2 수만큼 늘리면, 데이터가 리밸런싱되는 위치 계산이 쉽다.
예를 들어,
Mod1, 2 서버가 있다가 Mod3, 4 서버가 증설되었다면
- Mod0의 일부 데이터 -> Mod2
- Mod1의 일부 데이터 -> Mod3
Indexed
해당 key가 어디에 저장되어야 하는지 별도의 (인덱스) 서버가 따로 존재
- 서비스 디스커버리, 혹은 seq 테이블 처럼
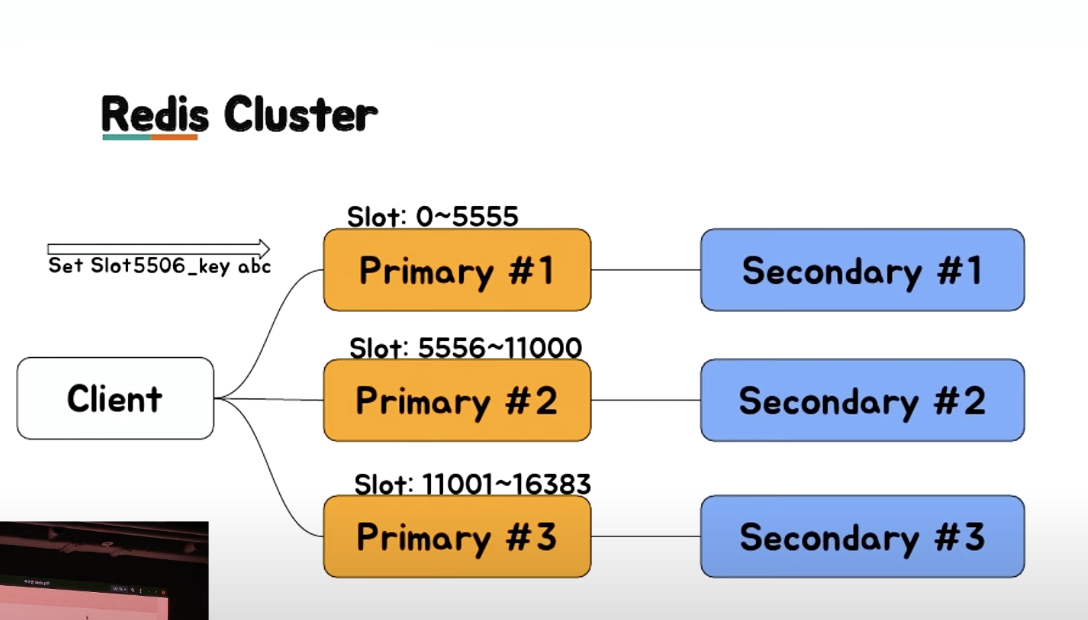
Redis Cluster #
Hash 기반으로 slot 16384 로 구분한다.
- Hash 알고리즘 :
CRC16 - slot = CRC16(key) % 16384
- 클러스터의 수는 16384를 넘어갈 수 없다는 것을 의미하기도 한다.
- key 가 key{hashkey} 패턴이면, 실제 crc16에 hashkey가 사용된다. (?)
- 위와 같은 패턴이면, 원하는 서버 쪽으로 보낼 수 있다고 한다.
- 좀 더 찾아볼 것
- 특정 Redis 서버는 이 slot range 를 가지고 있고, 데이터 migration 은 이 slot 단위의 데이터를 다른 서버로 전달하게 된다. (migrateCommand 이용)
좀 더 찾아볼 것
장점
- 자체적인 primary, secondary Failover
- slot 단위의 데이터 관리
단점
- 메모리 사용량이 더 많음
- slot 관리
- Migration 자체는 관리자가 시점을 결정해야 함
- slot 을 어디로 옮기겠다 등등 (?)
- library 구현이 필요함
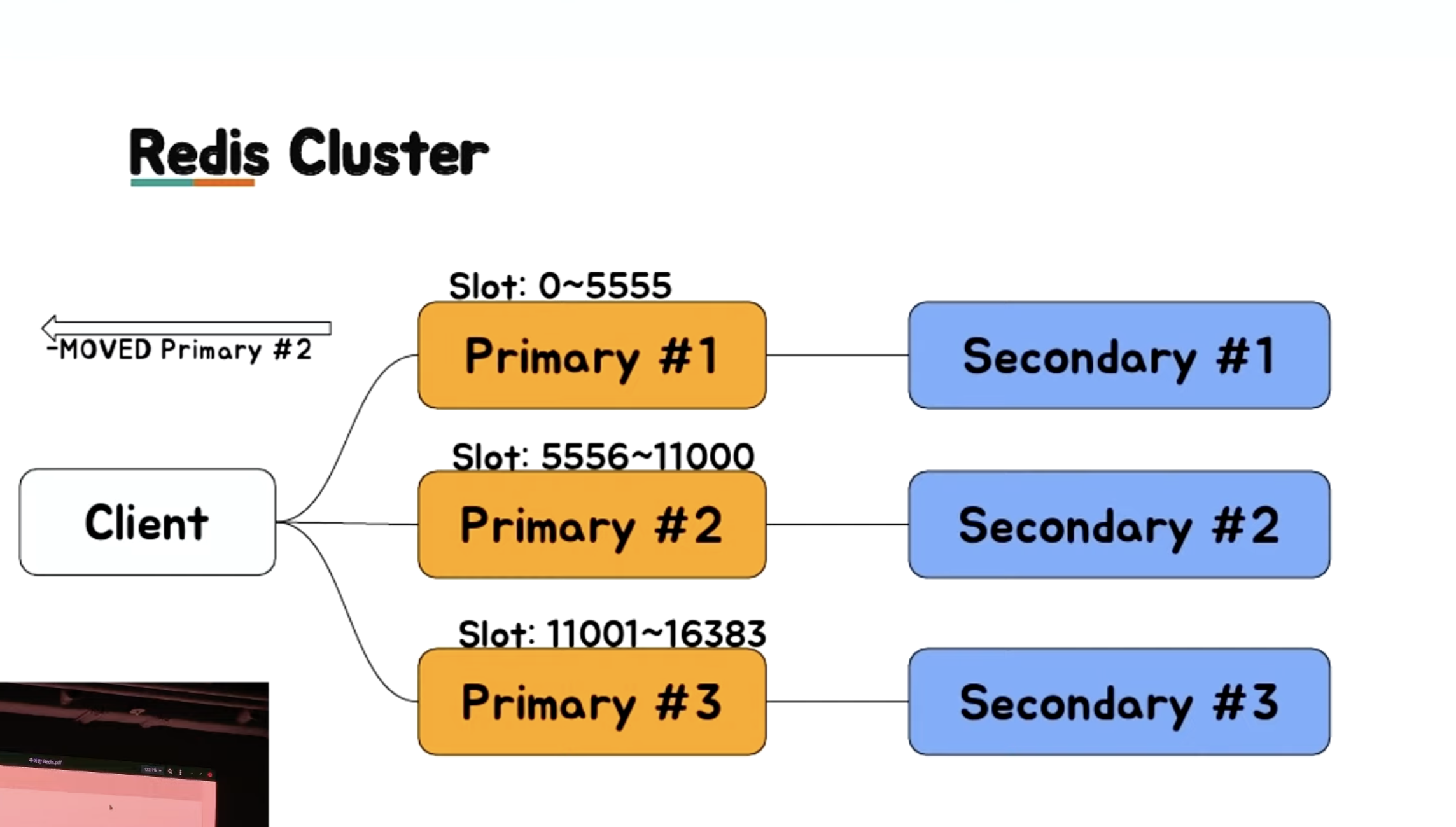
일반적인 라이브러리는 MOVED 처리를 해준다.
- 직접 개발 시에는 이 부분을 직접 구현해야한다.
Redis Failover #
- Coordinator 기반 Failover
- 클라이언트의 추가적인 구현이 필요하다.
- VIP/DNS 기반 Failover
- 클라이언트의 추가적인 구현이 필요 없다.
- VIP 기반 :
- 외부로 서비스를 제공해야 하는 서비스 업자에 유리 (ex : 클라우드 업체)
- Domain 기반 :
- DNS Cache TTL 을 관리해야 한다.
- 사용하는 언어별 DNS 캐싱 정책을 잘 알아야 한다.
- 툴(클라이언트)에 따라서 한번 가져온 DNS 정보를 다시 호출하지 않는 경우도 존재한다.
- ex : java 30초, …
- 위와 같은 특징이 있긴 하지만, DNS 가 살짝 더 편하긴한다.
- 서비스 특징마다 선택할 수 있도록 해야 한다.
- Redis Cluster 사용
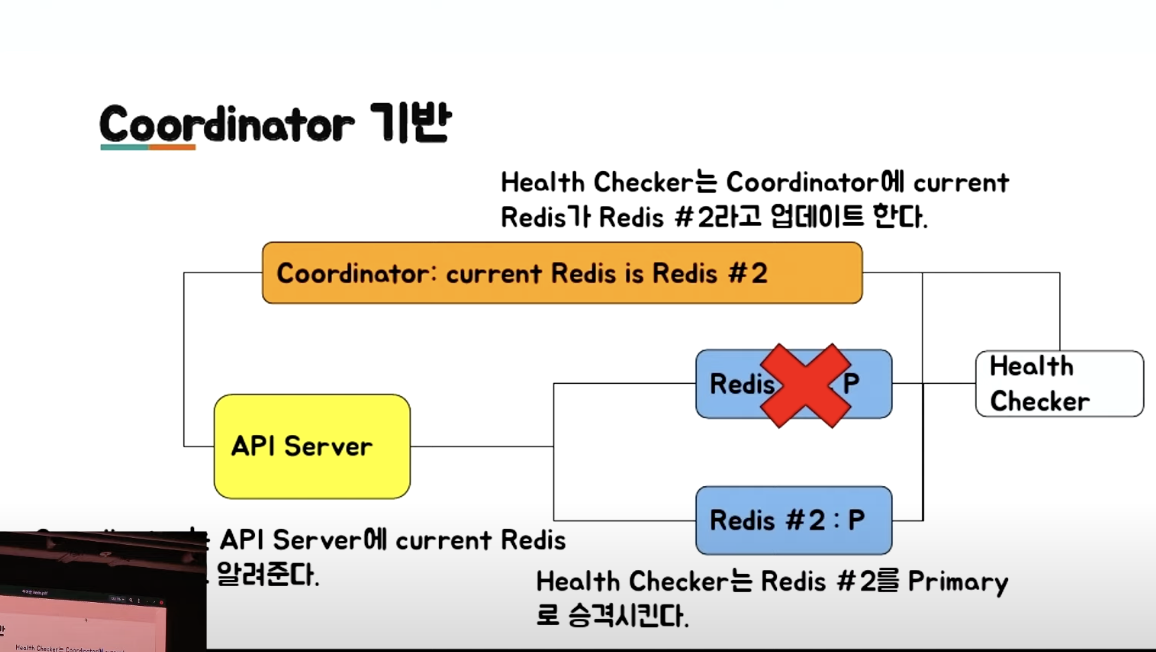
Coordinator 기반 Failover #
- Coordinator 기반으로 설정/관리하면 동일한 방식으로 관리 가능 (IaC 느낌을 말하는 듯)
- 아래 그림과 같이, 기능을 이용하도록 개발 필요
VIP(Virtual IP) 기반 Failover #
- 레디스 서버에 실제 IP 말고 VIP를 추가로 부여한다.
- 클라이언트는 VIP 를 통해서만 Redis에 접속한다.
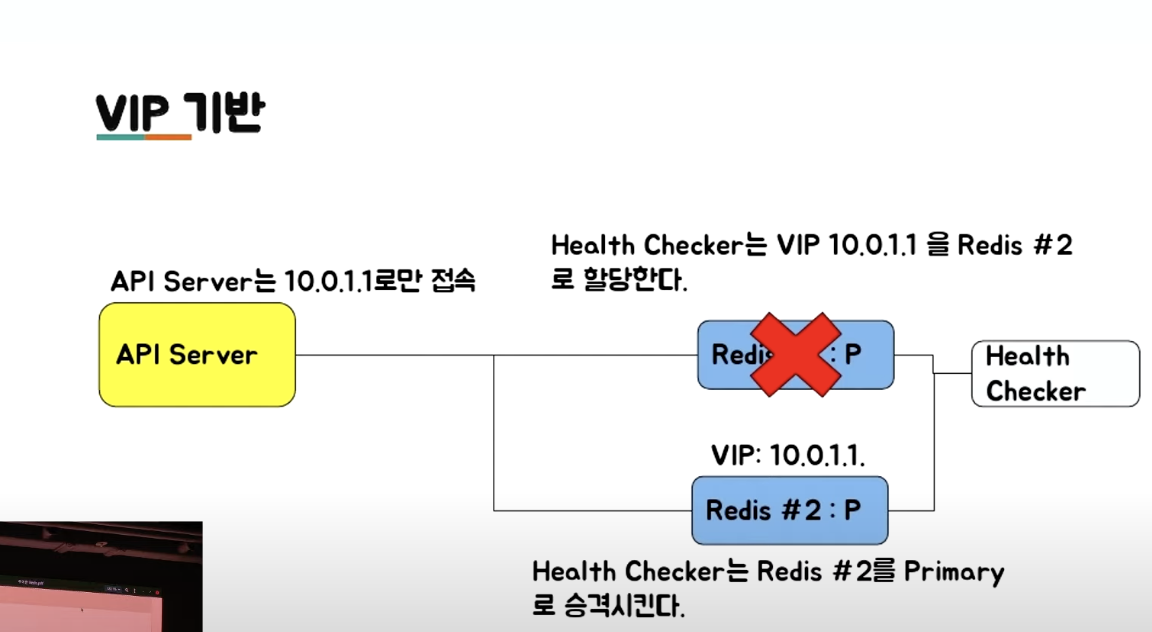
주의할 점
- Failover 시, 기존 서버의 연결을 모두 끊어줘야 한다.
- 클라이언트의 재접속을 유도한다.
DNS 기반 Failover #
VIP 와 동일한 개념이다.
Domain 을 이용하는 차이다.
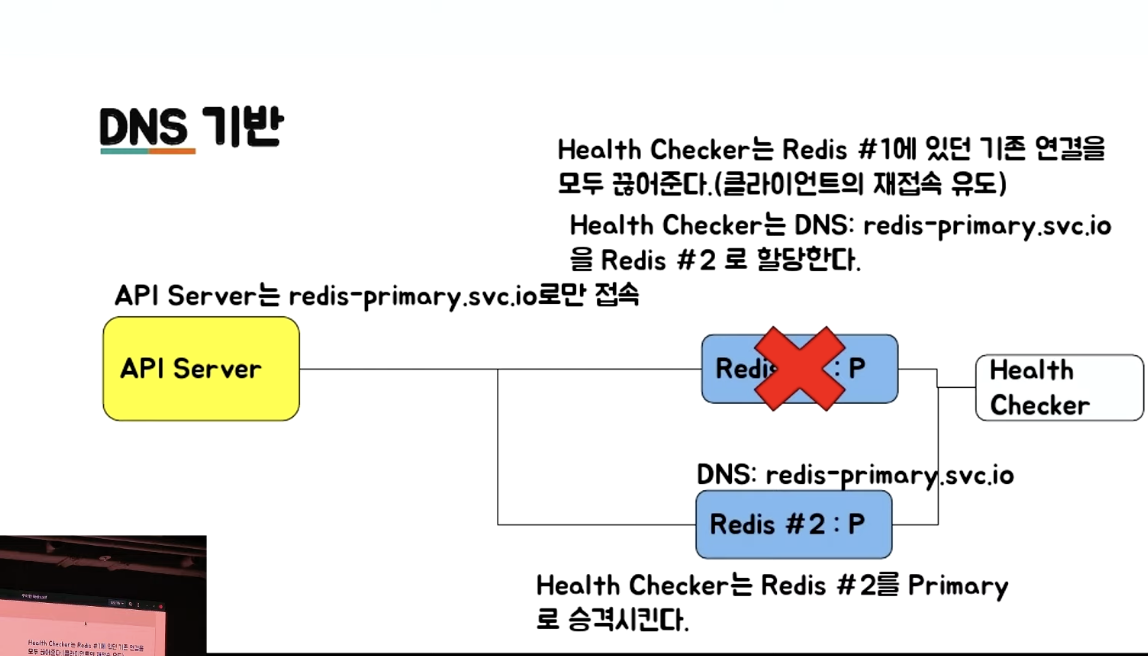
주의할 점
- Failover 시, 기존 서버의 연결을 모두 끊어줘야 한다.
- 클라이언트의 재접속을 유도한다.
Monitoring #
Redis 에서 확인해야할 것 #
- RSS
- 꼭 모니터링 해야한다.
- 물리 메모리를 얼마나 쓰고 있는지에 대한 정보
- Used Memory
- (Redis 가 판단하는) 사용하고 있는 메모리 정보
- RSS와 차이가 있다.
- Connection 수
- 초당 처리 요청 수
System 자체에서 확인해야할 것 #
- CPU
- DISK
- Network rx/tx
- 너무 많은 데이터를 처리하면, 네트워크 단(패킷)에서 Drop 되는 경우가 생겨서 문제(?)가 발생할 수도 있다고 한다.
CPU가 100%를 칠 경우 #
처리량이 매우 많다면?
- Scale Up
- 실제 CPU 성능에 영향을 받는다.
- 단순 get/set 은 초당 10만 이상처리 가능
O(n) 계열의 특정 명령이 많은 경우
monitor명령어를 통해 명령 패턴을 파악할 수 있다.monitor명령어를 잘못 쓰면, 오히려 부하 발생시킬 수 있다.- 짧게 쓰는 것이 좋다.
결론 #
1. Redis 는 매우 좋은 도구이다.
다만, 메모리를 빡빡하게 쓰기 시작하면서부터, 관리하기가 어려워진다.
- 32GB 장비라면, 24GB 이상 사용하면 장비 증설을 고려하는 것이 좋다.
- 넉넉하게 사용하는 것이 좋다.
- write 가 heavy할 때는 migration 도 매우 주의해야 한다.
- write 가 heavy 할 때는, 사실 뭘 쓰든 문제가 발생할 수 있다.
2. client-output-buffer-limit 설정이 필요하다.
메모리가 커질수록, 크게 잡아야된다.
이 값보다 크면 연결을 끊는다.
좀 더 찾아볼 것
3. Redis as Cache 로 사용한다면, 문제가 발생하더라도 영향력이 적다
Cache는 어처피 Cache 이다.
- Redis가 문제가 있을 때 DB등의 부하가 어느정도 증가하는지 확인이 필요하다.
- DB가 못버틸정도면, 문제이지만
- DB가 버틸정도면, 캐시는 다시 만들면 된다.
- Consistent Hashing 도 실제 부하를 아주 균등하게 나눠주지는 않는다.
- Adaptive Consistent Hasing 을 이용해 볼 수도 있다.
4. Redis as Persistent Store 로 사용한다면, 문제 발생 시 영향력이 크다.
- 무조건 primary/secondary 구성이 필요하다.
- 메모리를 절대 빡빡하게 사용하면 안된다.
- 정기적인 migration 필요
- (migration 작업이 생각보다 너무 많다.) 가능하면 자동화 도구를 만들어서 이용한다.
- RDB/AOF가 필요하다면, Secondary에서만 구동한다.
- RDB 보다는 AOF (?)
- 찾아볼 것
- 영속성 도구로써는 사실 권장하지는 않는 듯 하다.
- 문제가 발생할 여지가 많다.