Karpenter
오토스케일링 솔루션에 대한 고민 #
무신사는 ASG를 적극적으로 활용하고 있다.
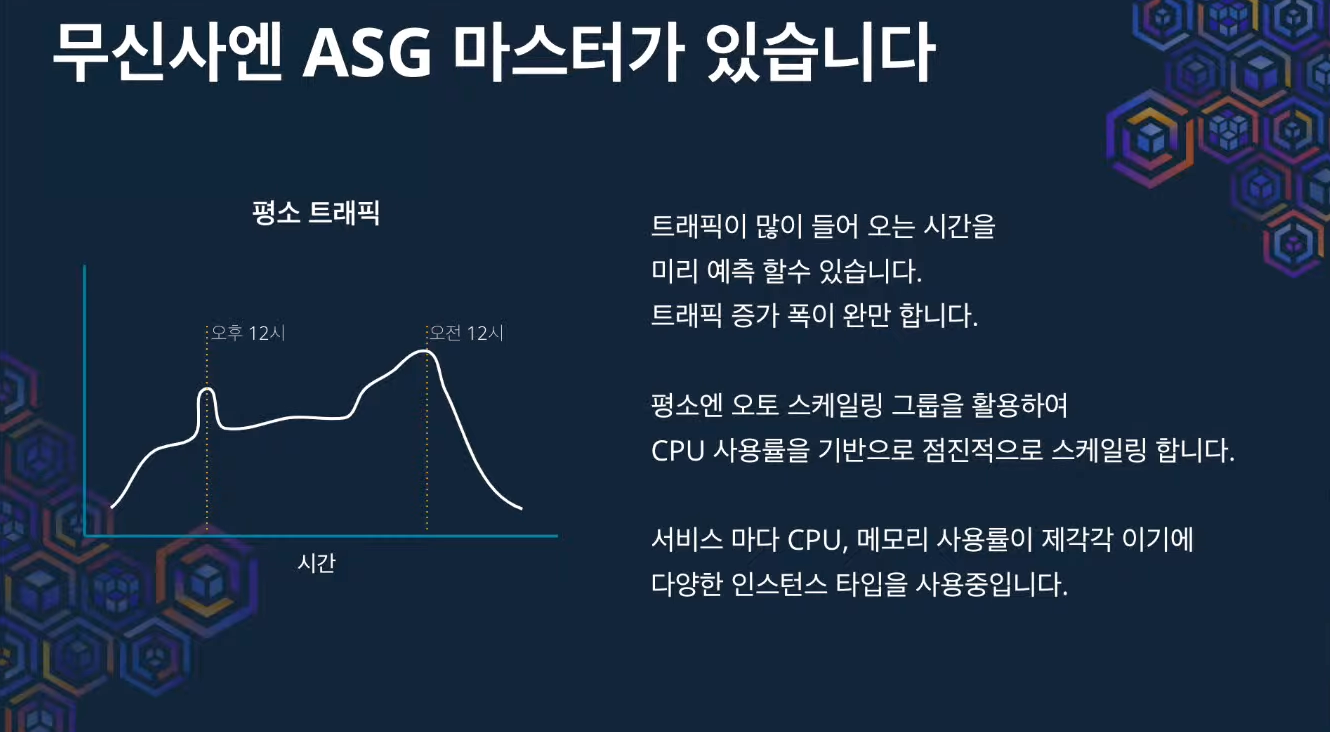
- (평소의)트래픽에 대한 예측이 (나름) 가능하다.
- 많이 들어오는 비슷하다.
- 트래픽 증가 폭이 완만하다.
- 평소에는 ASG 활용해서 CPU 사용률을 기반으로 점진적으로 스케일링 한다.
- 서비스 마다 CPU, 메모리 사용률이 제각각이기에 다양한 인스턴스 타입을 사용 중이다.
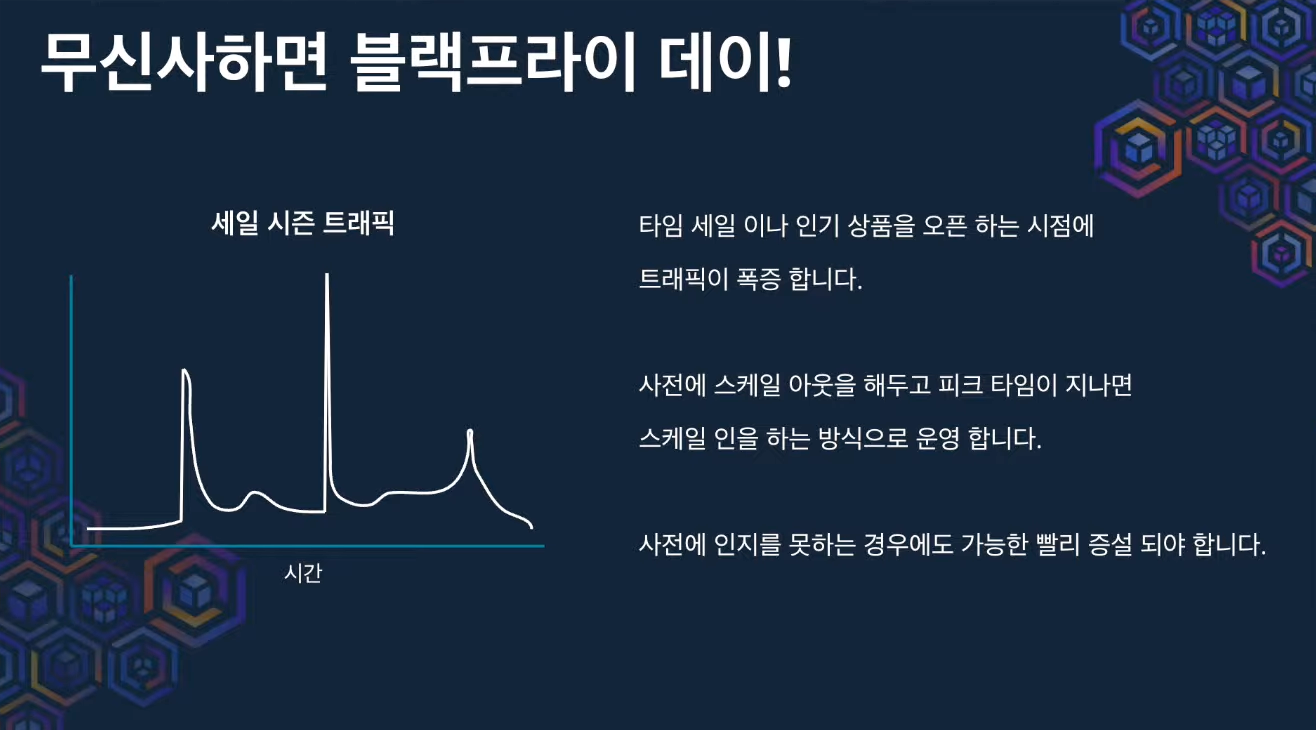
다만, 이벤트 기간에는 다르다.
- 사전에 미리 스케일 아웃 해둔다.
- 사전에 인지 못해도, 가능한 빨리 스케일 아웃될 수 있어야 한다.
:zap: 따라서, 스케일 인/아웃 모두 빠르면서 서비스에 적합한 인스턴스를 비용-효율적으로 운영해야 한다.
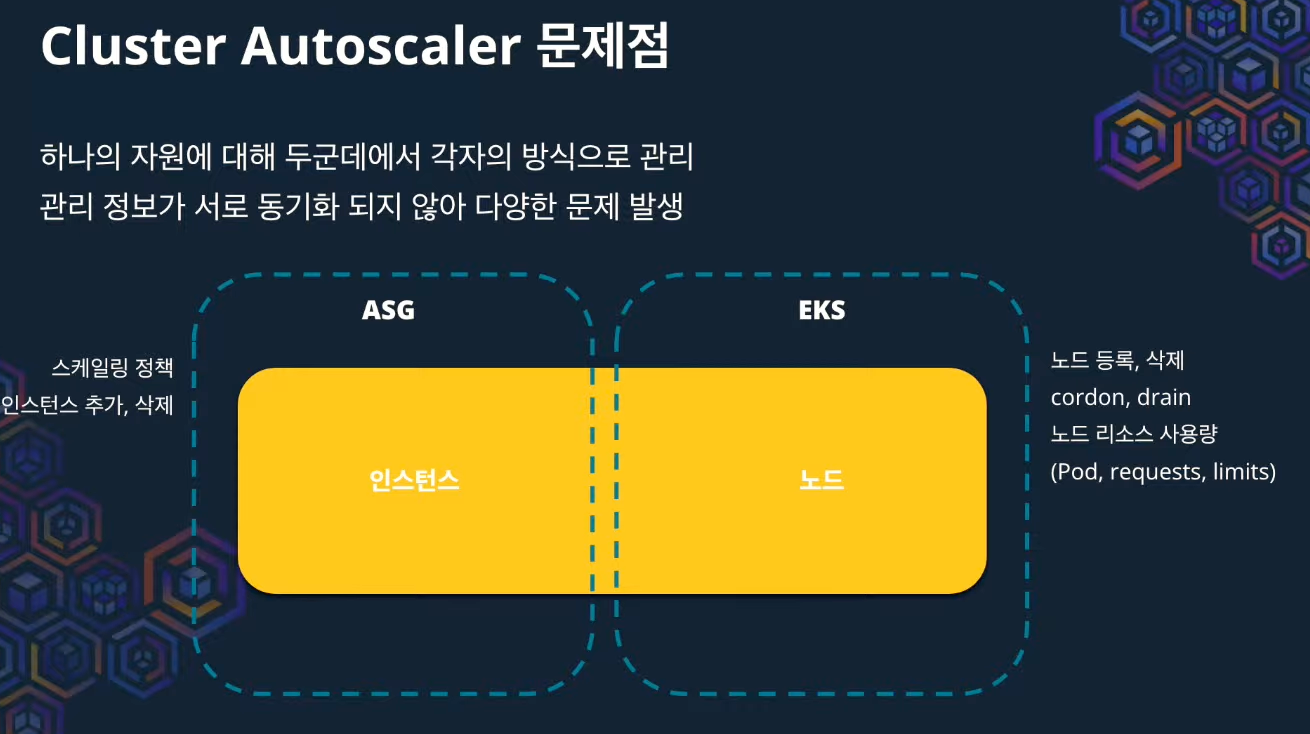
Cluster Autoscaler 및 단점 #
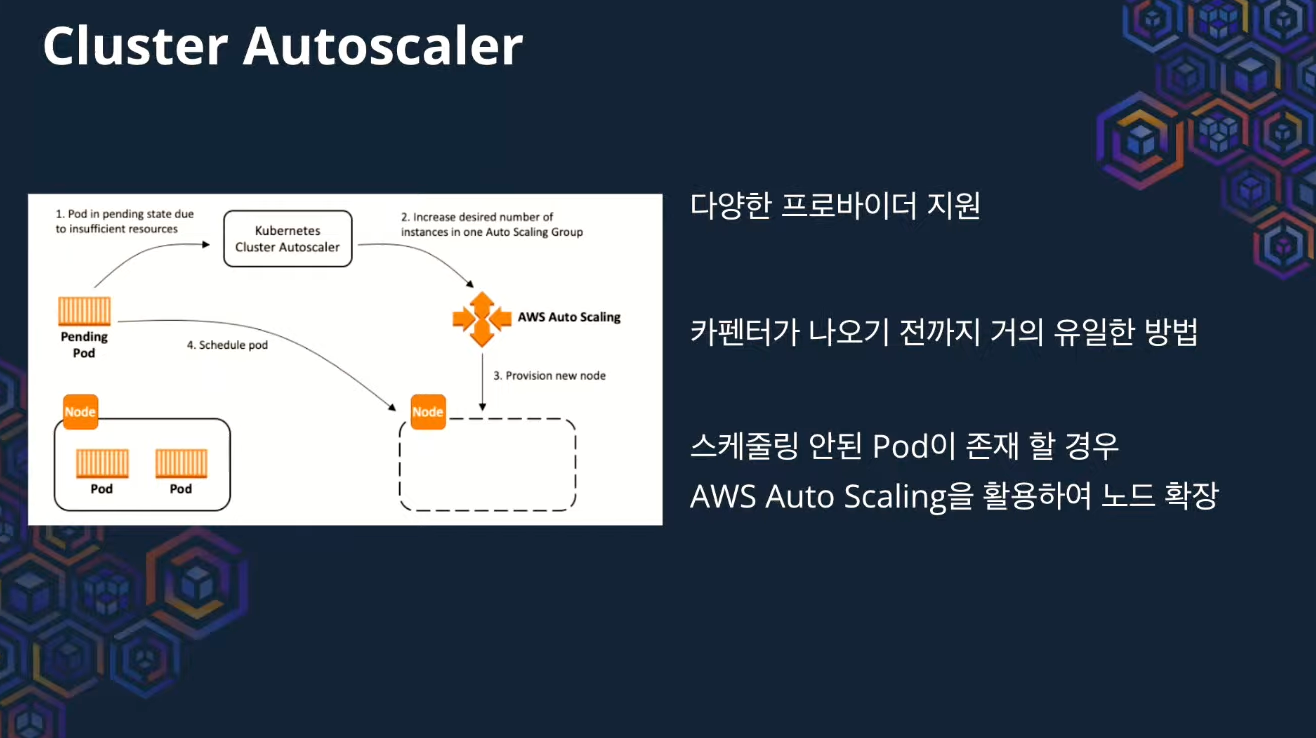
기존에는 Cluster Autoscaler 를 사용해왔다. 당시에는 k8s로 이전하는 것에 중점을 뒀다.
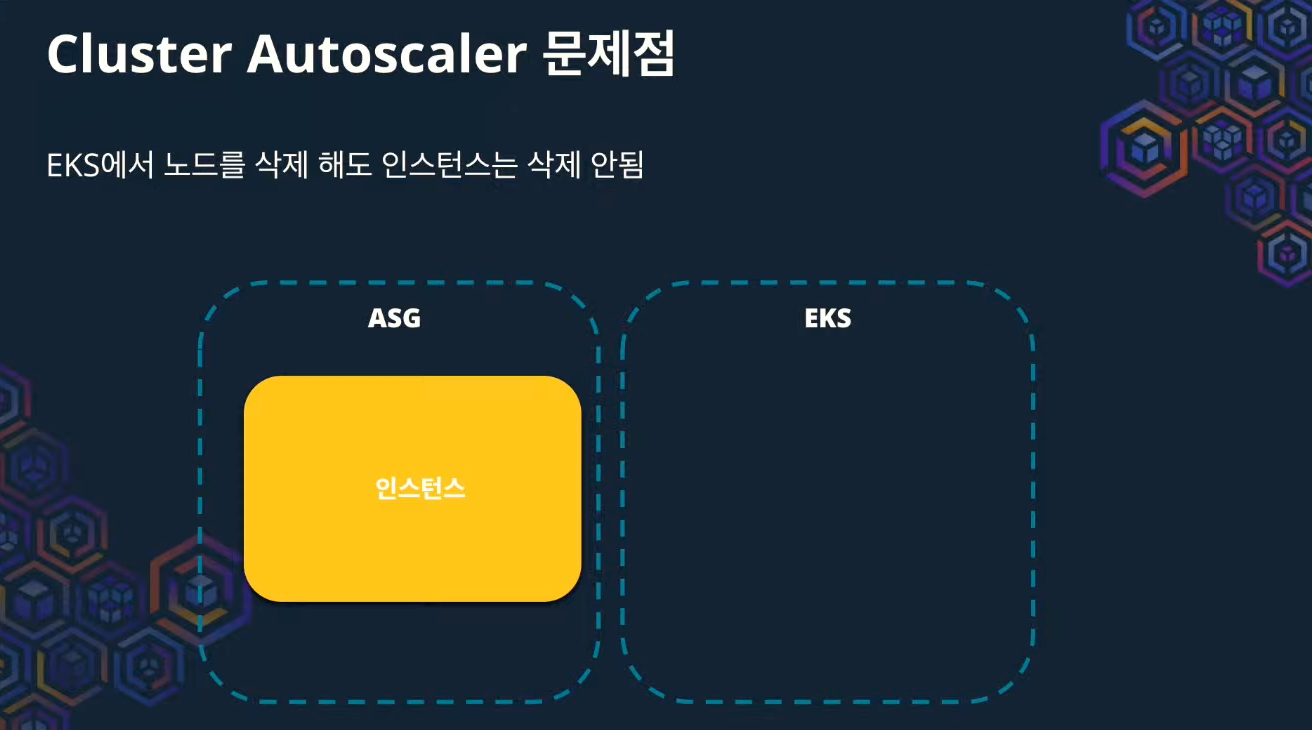
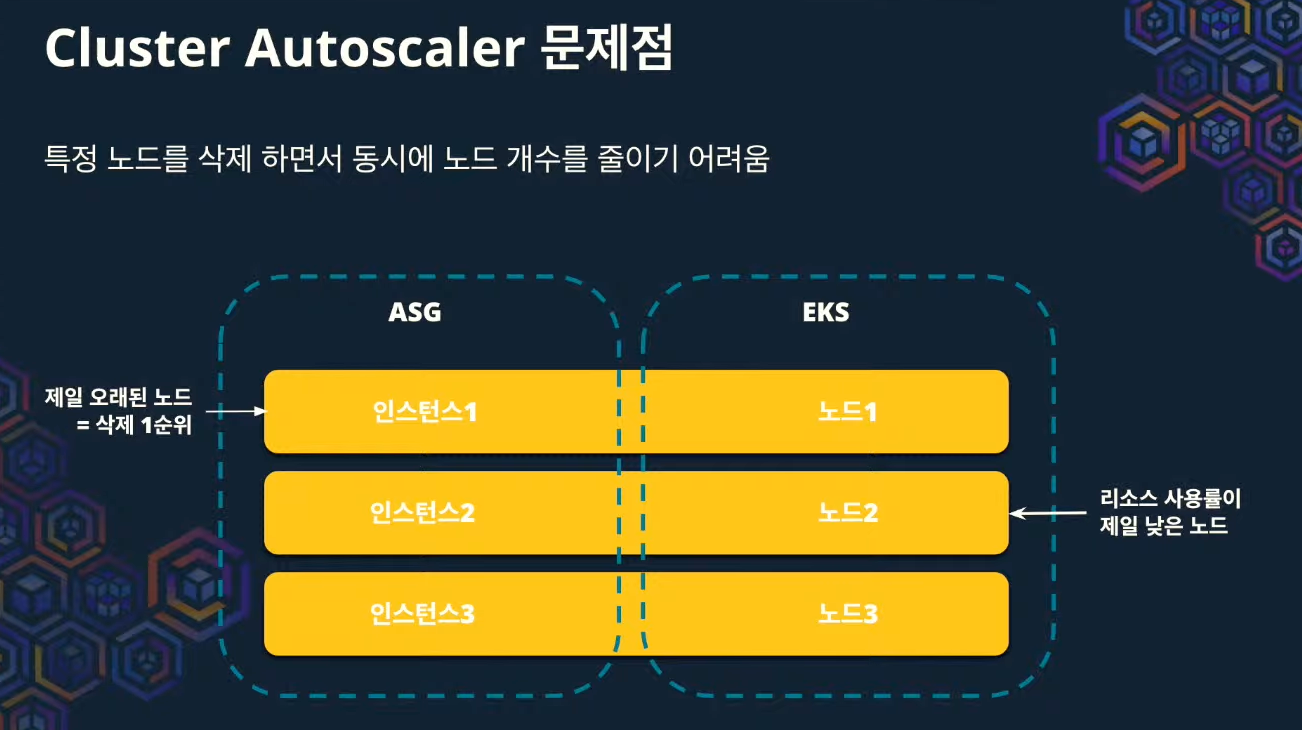
ㄴ 수동으로 노드를 삭제한 경우?

Karpenter (카펜터, K8S Native AutoScaler) #
아직 레퍼런스가 많지는 않다.
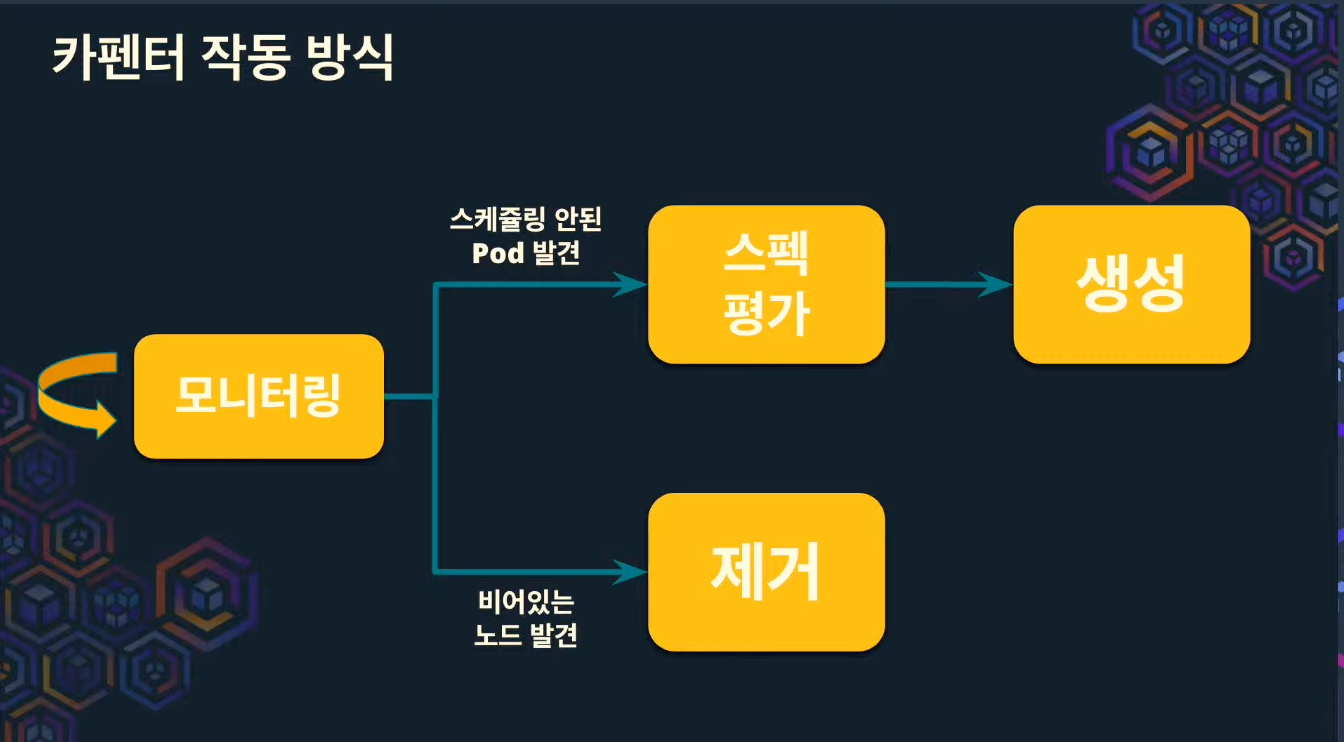
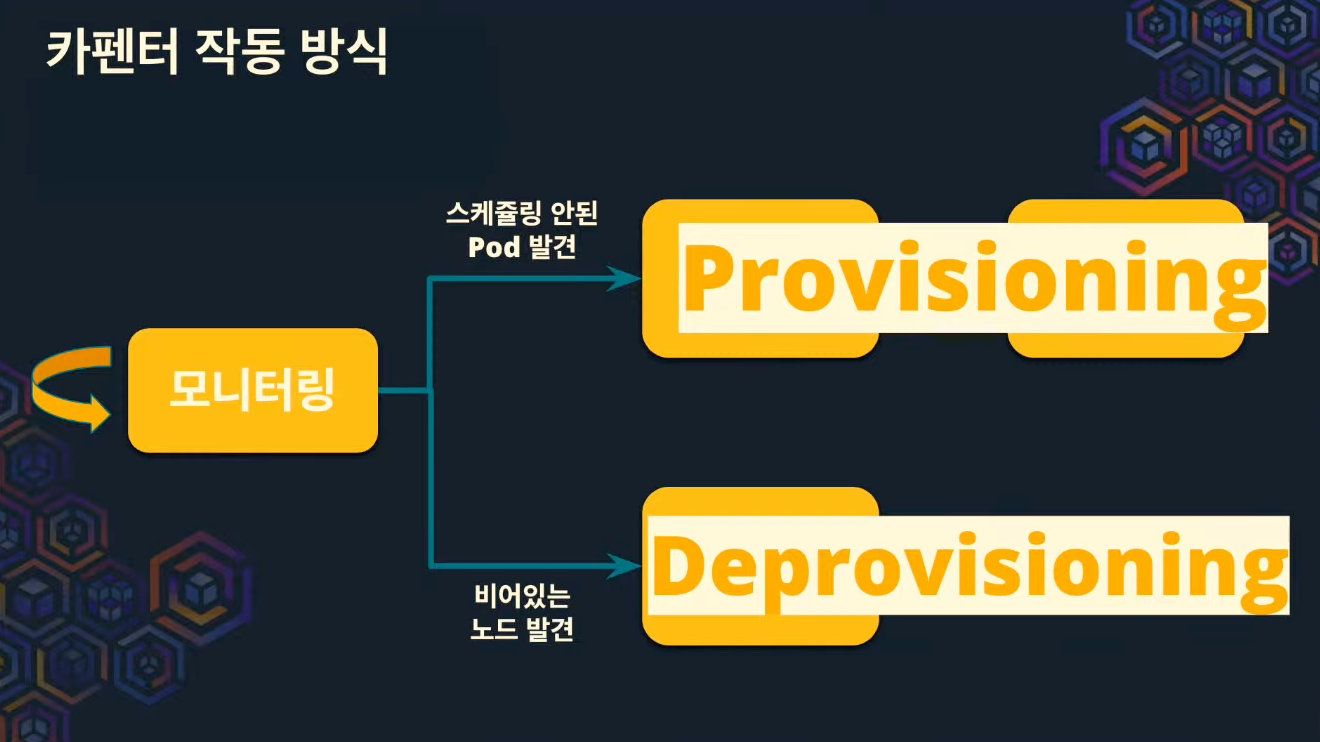
어떻게 작동하는지? #
pod에 대한 모니터링이 pulling 방식이 아닌 pub/sub 방식으로 동작한다.
따라서, 이벤트(메시지)가 발생하자마자 스케줄링이 동작한다. (Cluster Autoscaler의 pulling 방식은 주기적으로 동작하니까, 실시간적으로 동작 하지 않는 특징이 있다.)


시작 템플릿이 필요 없다.

ASG의 경우 시작 템플릿(launch template?)이 필요한데, 애는 필요하지 않다.
Resource Id, Tag 기반으로 리소스를 시작할 수 있다.
AMI 를 지정하지 않으면, 가장 최신의 EKS 최적화 AMI로 증설된다.
인스턴스 타입은 가드레일 방식으로 선언 가능하다.

Pod 에 적합한 인스턴스 중 가장 저렴한 인스턴스로 증설된다.

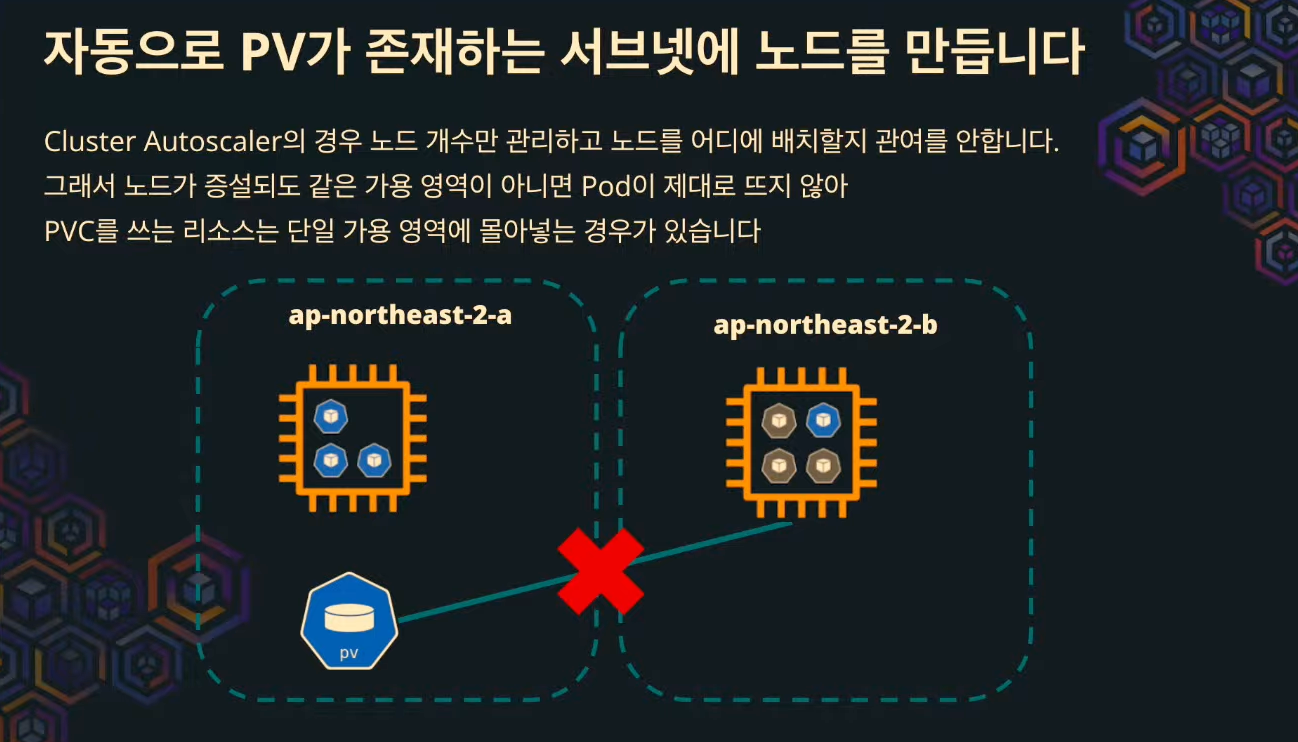
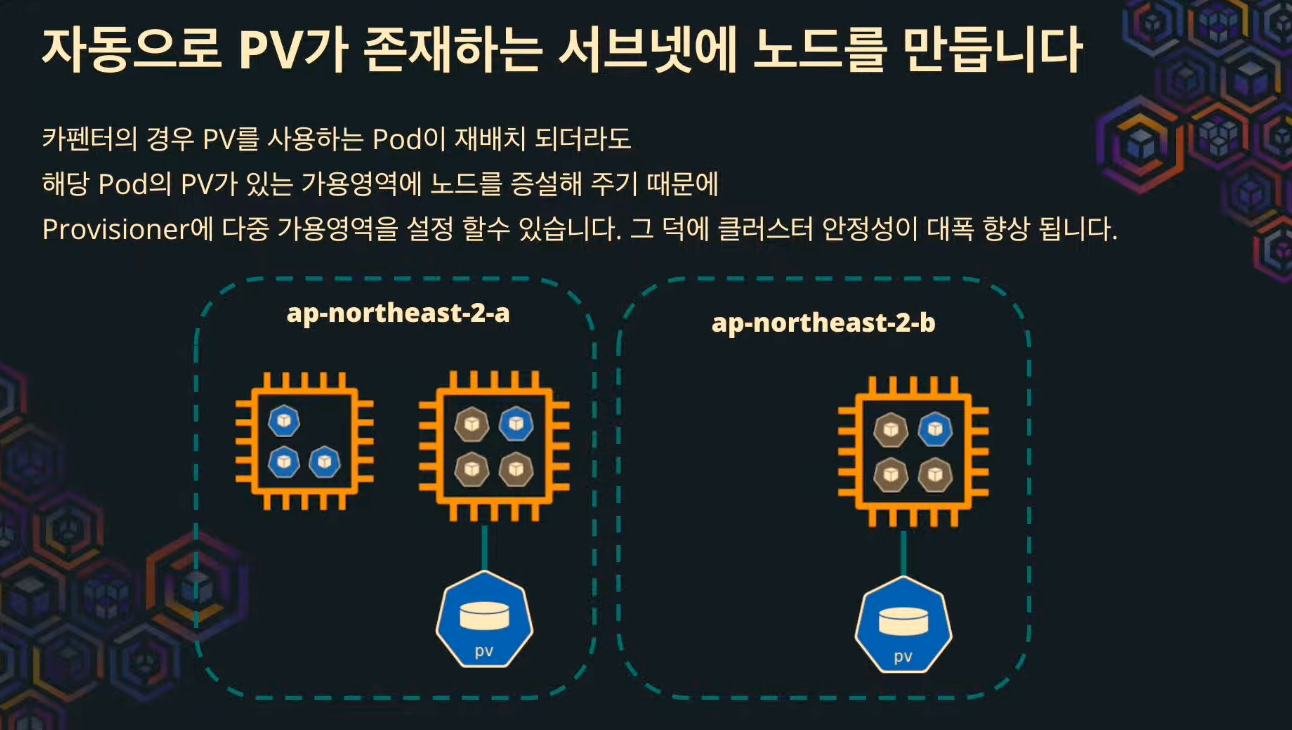
PV를 위해 단일 서브넷에 노드 그룹을 만들 필요가 없다.
가중치 기반으로 배포될 인스턴스 타입을 설계할 수 있다.
…
사용 안하는 노드는 자동으로 정리한다.
…
일정 기간이 지나면 자동으로 노드를 만료시킨다.

노드가 제때 drain 되지 않으면, 비효율적으로 운영될 수 있다.

노드를 줄여도 다른 노드에 충분한 여유가 있다면 자동으로 정리해준다.
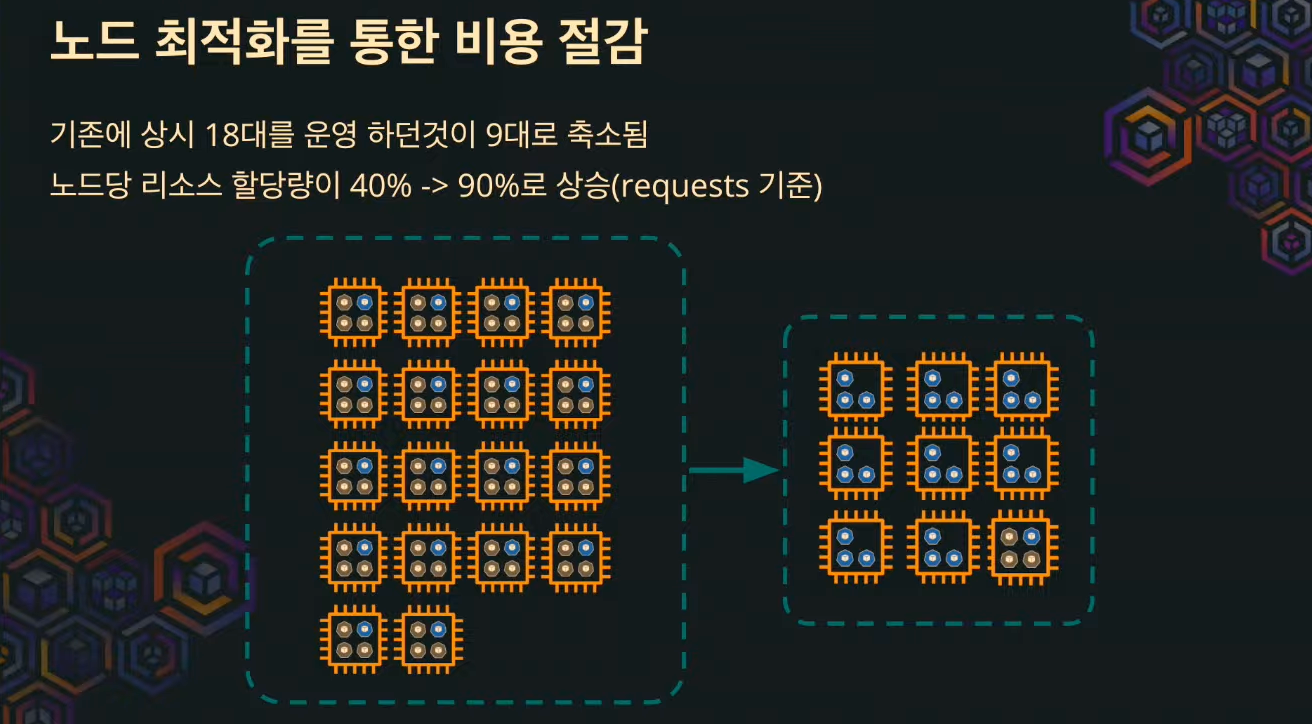
노드 최적화를 해준다.(비용을 줄일 수 있도록 노드를 자동으로 합쳐준다.)
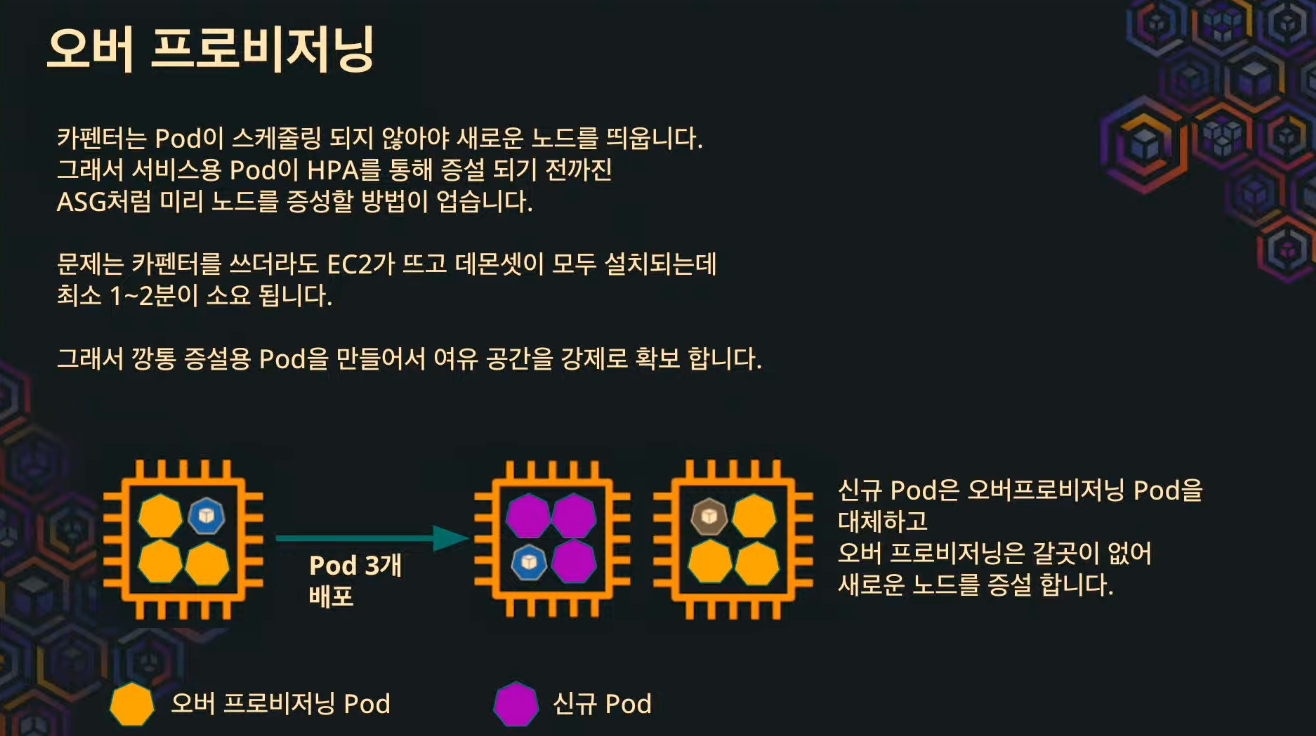
카펜터에 문제(= 노드 띄우는 시간)도 있다.

위 문제는 다음과 같이 해결했다.